Pandas 에서 2차원 data를 Stack, unstack, melt 를 이용해 복합 인덱스를 사용할 수 있고 Pivot 을 이용해 특정 데이터 중심의 2차원 데이터로 생성할 수 있다.
Pivot
Stack & Unstack
Melt
1 2 import pandas as pdimport numpy as np
2차원 테이블 행과 열로 구성된 데이터 집합
1 2 3 4 5 6 7 df = pd.DataFrame( {'foo' : ['One' ,'One' ,'One' ,'Two' ,'Two' ,'Two' ], 'bar' : ['A' ,'B' ,'C' ,'A' ,'B' ,'C' ], 'baz' : [1 ,2 ,3 ,4 ,5 ,6 ] , 'zoo' : ['x' ,'y' ,'z' ,'q' ,'w' ,'t' ]} ) df
foo
bar
baz
zoo
0
One
A
1
x
1
One
B
2
y
2
One
C
3
z
3
Two
A
4
q
4
Two
B
5
w
5
Two
C
6
t
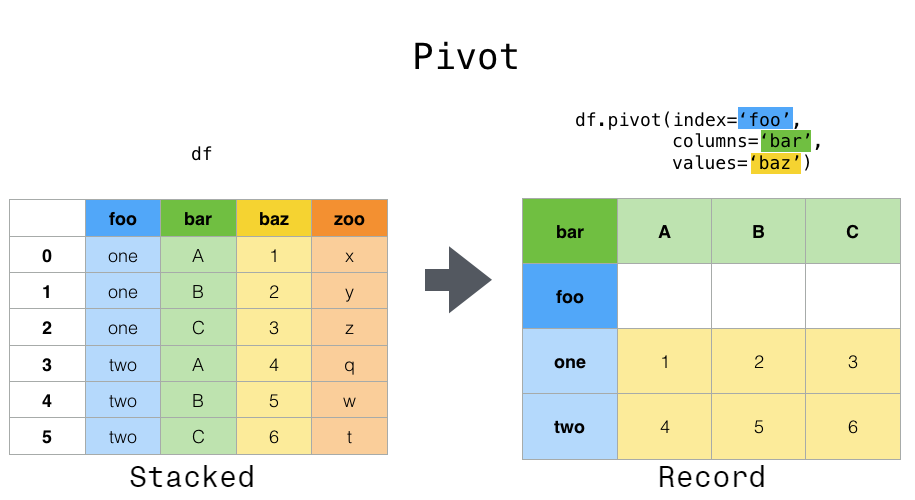
Pivot 피봇/피봇 테이블은 2차원 데이터 열에서 공통된 부분을 중심으로 새 테이블 집합을 형성하게 해준다. 피봇은 index, columns, values 라는 이름을 가진 세 가지 parameter를 취한다. 이러한 각 파라미터의 값으로 원래 표에 열 이름을 지정해야 한다.
foo, bar, baz, zoo 컬럼 중에서 foo 에 대해서 정리를 하고 bar 를 컬럼으로 지정하면 아래와 같다.
1 2 df_pivot = df.pivot_table(index='foo' , columns='bar' , values='baz' ) df_pivot
bar
A
B
C
foo
One
1
2
3
Two
4
5
6
ex) nba 데이터를 포지션의 연령별 연봉 테이블로 전환 1 2 dfnba = pd.read_csv('../data/nba.csv' ) dfnba
Name
Team
Number
Position
Age
Height
Weight
College
Salary
0
Avery Bradley
Boston Celtics
0.0
PG
25.0
6-2
180.0
Texas
7730337.0
1
Jae Crowder
Boston Celtics
99.0
SF
25.0
6-6
235.0
Marquette
6796117.0
2
John Holland
Boston Celtics
30.0
SG
27.0
6-5
205.0
Boston University
NaN
3
R.J. Hunter
Boston Celtics
28.0
SG
22.0
6-5
185.0
Georgia State
1148640.0
4
Jonas Jerebko
Boston Celtics
8.0
PF
29.0
6-10
231.0
NaN
5000000.0
...
...
...
...
...
...
...
...
...
...
453
Shelvin Mack
Utah Jazz
8.0
PG
26.0
6-3
203.0
Butler
2433333.0
454
Raul Neto
Utah Jazz
25.0
PG
24.0
6-1
179.0
NaN
900000.0
455
Tibor Pleiss
Utah Jazz
21.0
C
26.0
7-3
256.0
NaN
2900000.0
456
Jeff Withey
Utah Jazz
24.0
C
26.0
7-0
231.0
Kansas
947276.0
457
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
NaN
458 rows × 9 columns
1 pd.options.display.float_format = "{:,.2f}" .format
컬럼의 데이터에 공통된 모습이 많이 보인다. 이 중에서 포지션을 기준으로 나이에 따른 연봉을 본다고 가정하면 포지션을 인덱스로하고 나이를 컬럼으로 지정하면 아래와 같다.
1 2 dfnba.pivot_table(index='Position' , columns='Age' , values='Salary' )
Age
19.00
20.00
21.00
22.00
23.00
24.00
25.00
26.00
27.00
28.00
...
31.00
32.00
33.00
34.00
35.00
36.00
37.00
38.00
39.00
40.00
Position
C
NaN
5,143,140.00
1,571,000.00
3,476,698.20
2,121,999.50
4,532,003.33
10,881,995.00
3,041,850.82
5,004,260.50
7,635,761.83
...
10,338,218.00
8,208,695.50
9,500,000.00
6,258,000.00
7,448,760.00
947,276.00
NaN
222,888.00
NaN
5,250,000.00
PF
NaN
2,369,838.00
2,397,408.00
1,601,105.80
2,399,120.50
2,577,551.44
2,195,476.60
7,228,086.75
9,217,098.43
5,268,839.17
...
5,323,787.00
14,346,365.00
2,630,241.40
6,469,277.50
2,624,593.50
2,877,470.00
6,666,667.00
NaN
NaN
8,500,000.00
PG
NaN
3,316,290.00
1,944,080.00
2,381,130.00
1,627,769.00
4,652,526.50
5,422,085.80
10,038,174.80
5,944,070.17
5,021,965.17
...
7,467,596.40
4,082,425.33
2,226,179.67
8,395,104.00
NaN
2,170,465.00
NaN
NaN
947,726.00
250,750.00
SF
NaN
1,979,976.00
1,404,480.00
2,401,364.60
2,760,134.36
5,067,491.60
3,382,640.73
7,322,325.20
10,532,567.00
1,996,608.71
...
10,960,320.25
9,720,195.75
NaN
261,894.00
947,276.00
1,721,559.75
25,000,000.00
3,376,000.00
NaN
NaN
SG
1,930,440.00
1,749,840.00
2,215,710.43
2,055,241.00
1,388,251.18
3,205,720.53
1,782,834.89
9,872,690.29
4,815,524.62
6,354,000.00
...
7,085,000.00
2,041,138.00
2,233,533.33
12,579,269.50
3,512,173.75
3,311,138.00
NaN
1,880,638.00
4,088,019.00
NaN
5 rows × 22 columns
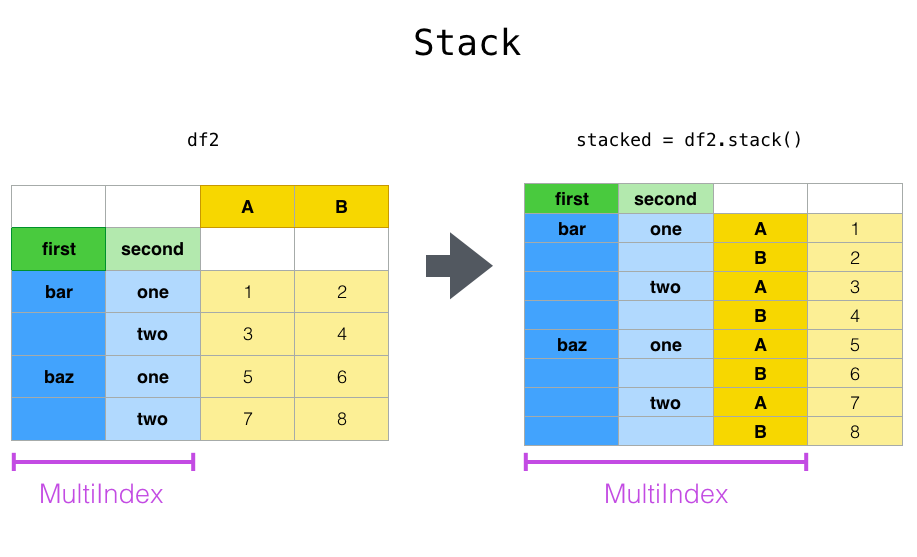
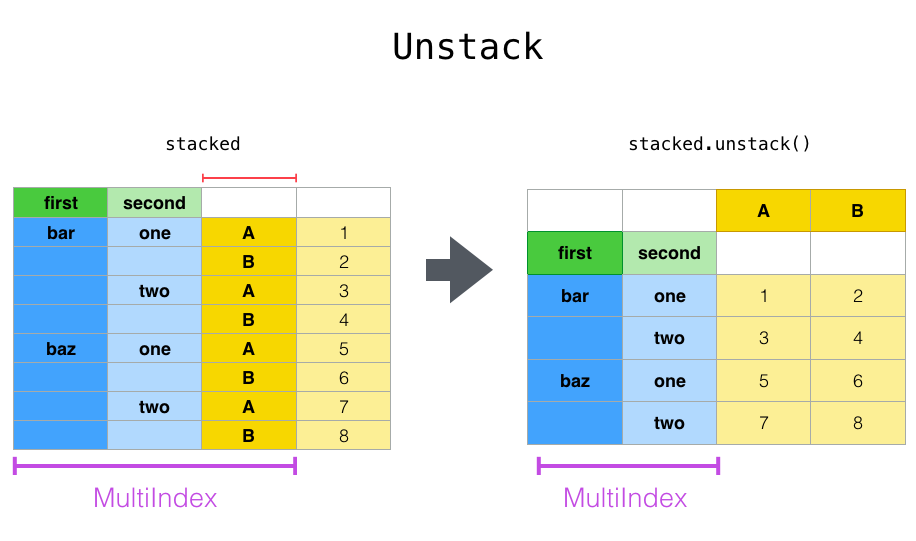
Stack & Unstack 2차원 테이블은 행 과 열이 순차적 값으로 교차하게 되어 있다. 스택은 컬럼의 값을 아래-위로 배치를 시킨다고 상상이 된다. 그래서 스택과 언스택은 이렇게 생각된다.
stack : 2차원 컬럼의 내용을 수직방향으로 쌓는 구조, 즉 새로운 인덱스가 더해진다.
unstack : 인덱스 구성요소를 한 단계 컬럼으로 만들며 수평방향으로 쌓게 한다.
stack
pandas reshaping
1 2 3 4 5 6 7 df_single_level = pd.DataFrame( [['Mostly cloudy' , 10 ], ['Sunny' , 12 ]], index=['London' , 'Oxford' ], columns=['Weather' , 'Wind' ] ) df_single_level
Weather
Wind
London
Mostly cloudy
10
Oxford
Sunny
12
index와 weather, wind 라는 컬럼을 stack을 호출하면 weather-wind 관련 인덱스를 생성하고 데이터를 나열한다.
London Weather Mostly cloudy
Wind 10
Oxford Weather Sunny
Wind 12
dtype: object
다른 데이터를 살펴보자.
1 2 3 4 5 6 7 8 9 10 11 12 tuples = list ( zip ( *[ ["bar" , "bar" , "baz" , "baz" , "foo" , "foo" , "qux" , "qux" ], ["one" , "two" , "one" , "two" , "one" , "two" , "one" , "two" ], ] ) ) index = pd.MultiIndex.from_tuples(tuples, names=["first" , "second" ]) df = pd.DataFrame(np.random.randn(8 , 2 ), index=index, columns=["A" , "B" ]) df
A
B
first
second
bar
one
-1.301694
-0.013259
two
-0.197846
0.879890
baz
one
0.718211
-0.739434
two
-0.140217
0.071260
foo
one
-1.142268
-2.606413
two
1.119145
0.109402
qux
one
-0.504167
-1.703280
two
1.064976
1.011060
위 데이터는 stack()을 하면 A, B 컬럼이 MultiIndex 로 추가되며 A, B 컬럼 데이터 포인트가 배치된다.
first second
bar one A -1.301694
B -0.013259
two A -0.197846
B 0.879890
baz one A 0.718211
B -0.739434
two A -0.140217
B 0.071260
foo one A -1.142268
B -2.606413
two A 1.119145
B 0.109402
qux one A -0.504167
B -1.703280
two A 1.064976
B 1.011060
dtype: float64
A
B
first
second
bar
one
-1.301694
-0.013259
two
-0.197846
0.879890
baz
one
0.718211
-0.739434
two
-0.140217
0.071260
1 2 stacked = df2.stack() stacked
first second
bar one A -1.301694
B -0.013259
two A -0.197846
B 0.879890
baz one A 0.718211
B -0.739434
two A -0.140217
B 0.071260
dtype: float64
Unstack
pandas reshaping
first second
bar one A -1.301694
B -0.013259
two A -0.197846
B 0.879890
baz one A 0.718211
B -0.739434
two A -0.140217
B 0.071260
dtype: float64
A
B
first
second
bar
one
-1.301694
-0.013259
two
-0.197846
0.879890
baz
one
0.718211
-0.739434
two
-0.140217
0.071260
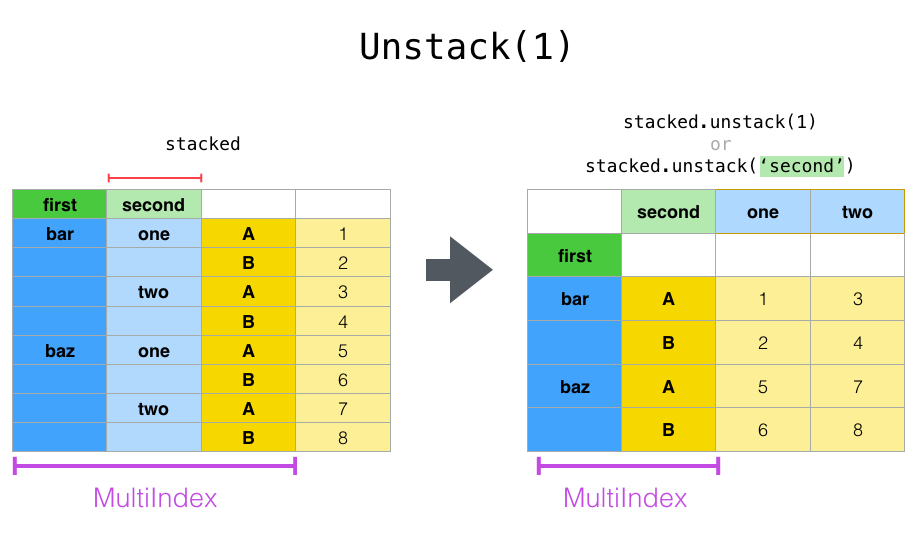
레벨을 지정
second
one
two
first
bar
A
-1.301694
-0.197846
B
-0.013259
0.879890
baz
A
0.718211
-0.140217
B
-0.739434
0.071260
A
B
first
second
bar
one
-1.301694
-0.013259
two
-0.197846
0.879890
baz
one
0.718211
-0.739434
two
-0.140217
0.071260
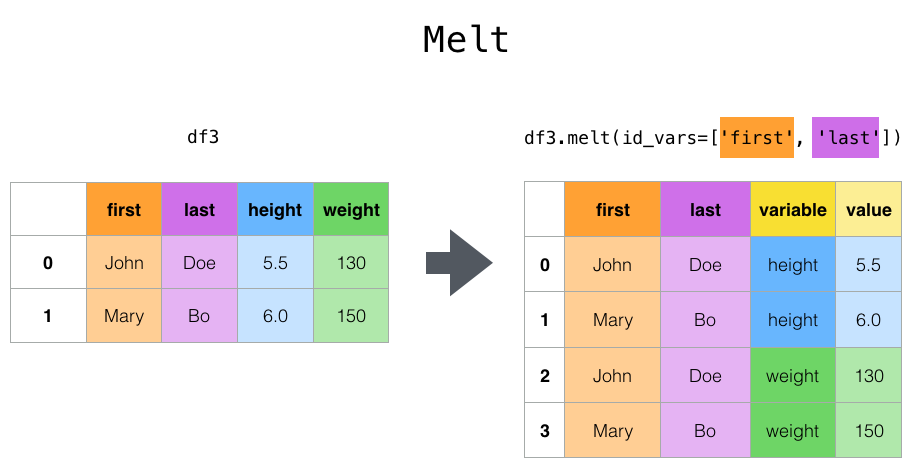
Melt melt() 는 ID 변수를 기준으로 원래 데이터셋에 있던 여러개의 칼럼 이름을 ‘variable’ 칼럼에 위에서 아래로 길게 쌓아놓고, ‘value’ 칼럼에 ID와 variable에 해당하는 값을 넣어주는 식으로 데이터를 재구조화합니다.
1 2 3 4 5 6 7 8 9 cheese = pd.DataFrame( { "first" : ["John" , "Mary" ], "last" : ["Doe" , "Bo" ], "height" : [5.5 , 6.0 ], "weight" : [130 , 150 ], } ) cheese
first
last
height
weight
0
John
Doe
5.50
130
1
Mary
Bo
6.00
150
1 2 cheese.melt(id_vars=['first' ,'last' ])
first
last
variable
value
0
John
Doe
height
5.50
1
Mary
Bo
height
6.00
2
John
Doe
weight
130.00
3
Mary
Bo
weight
150.00
1 cheese.melt(id_vars=['first' ,'last' ], value_name='quantity' )
first
last
variable
quantity
0
John
Doe
height
5.50
1
Mary
Bo
height
6.00
2
John
Doe
weight
130.00
3
Mary
Bo
weight
150.00
참고
pandas.DataFrame.stack