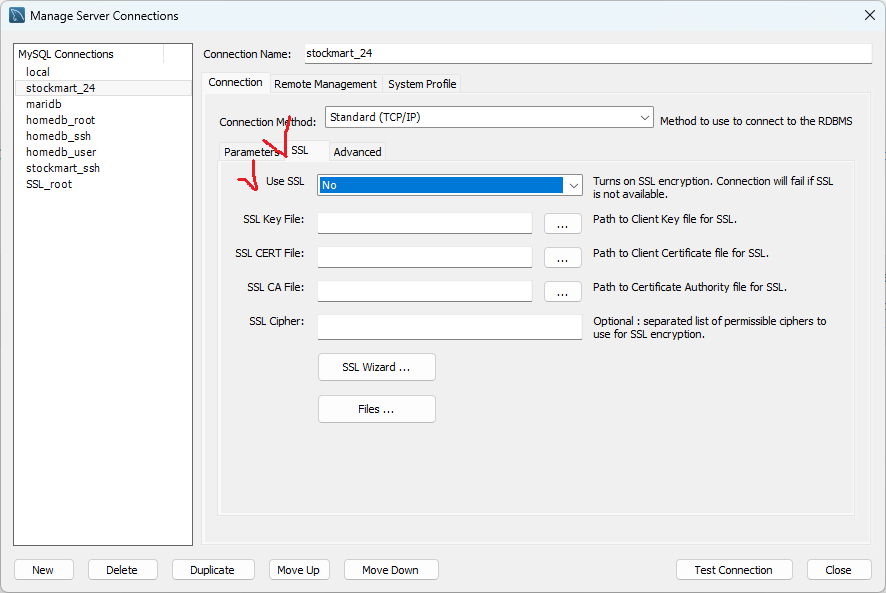
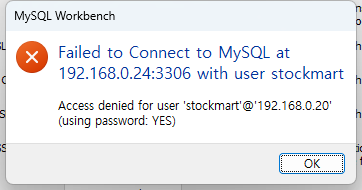
MariaDB / MySQL 에서 json data type을 사용할 수 있다.
MariaDB json tutorial
https://mariadb.com/ko/resources/blog/using-json-in-mariadb/
USE lecture;
CREATE TABLE locations (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
type CHAR(1) NOT NULL,
latitude DECIMAL(9,6) NOT NULL,
longitude DECIMAL(9,6) NOT NULL,
attr JSON,
PRIMARY KEY (id)
);
DESC locations;
INSERT INTO locations (type, name, latitude, longitude, attr) VALUES
(‘R’, ‘Lou Malnatis’, 42.0021628, -87.7255662,
‘{ “details”: {
“foodType”: “Pizza”,
“menu”: “https://www.loumalnatis.com/our-menu“
},
“favorites”: [{“description”: “Pepperoni deep dish”, “price”: 18.75},
{“description”: “The Lou”, “price”: 24.75}]}’);
SELECT * FROM locations;
– scala value
SELECT NAME, latitude, longitude,
JSON_VALUE(attr, ‘$.details.foodType’) AS Food
FROM locations;
– return object
SELECT NAME, latitude, longitude,
JSON_QUERY(attr, ‘$.details’) AS details
FROM locations;
SELECT NAME, latitude, longitude,
JSON_QUERY(attr, ‘$.favorites’) AS details
FROM locations;
– return values
SELECT NAME, latitude, longitude,
JSON_EXTRACT(attr, ‘$.details’) AS details
FROM locations;
creating INDEX
– virtual colunn 을 이용해 json_oject의 요소를 컬럼으로 만들고
– 이것을 인덱스로 지정한다.
ALTER TABLE locations ADD COLUMN
food_type VARCHAR(25) AS ( JSON_VALUE( attr, ‘$.details.foodType’)) VIRTUAL;
DESC locations;
CREATE INDEX foottypes ON locations(food_type);
modifying json data
– JSON_INSERT(): inserting new object
UPDATE locations
SET attr = JSON_INSERT(attr, ‘$.nickname’, ‘oh ben’)
WHERE id=1;
SELECT JSON_QUERY(attr, ‘$.nickname’) FROM locations;
SELECT JSON_EXTRACT(attr, ‘$.nickname’) FROM locations;
SELECT * FROM locations;
UPDATE locations
SET attr = JSON_INSERT(attr, ‘$.foodTypes’,
JSON_ARRAY(‘Asian’, ‘Mexican’))
WHERE id = 1;
SELECT JSON_EXTRACT(attr, ‘$.foodTypes’) FROM locations;
– JSON_ARRAY_APPEND() : adding array elements
UPDATE locations
SET attr = JSON_ARRAY_APPEND(attr, ‘$.foodTypes’, ‘German’)
WHERE id = 1;
SELECT JSON_QUERY(attr, ‘$.foodTypes’) FROM locations;
SELECT JSON_EXTRACT(attr, ‘$.foodTypes’) FROM locations;
– JSON_REMOVE(): REMOVING ARRAY ELEMENTS
UPDATE locations
SET attr = JSON_REMOVE(attr, ‘$.foodTypes[2]’) – German
WHERE id = 1;
SELECT JSON_EXTRACT(attr, ‘$.foodTypes’) FROM locations;
Hybrid querhying: sql, json 장점
– json object 생성
SELECT
JSON_OBJECT(‘name’, name, ‘latitude’, latitude, ‘longitude’, longitude) AS data
FROM locations;
– merging
SELECT JSON_MERGE(
JSON_OBJECT(
‘name’, name,
‘latitude’, latitude,
‘Longitude’, longitude),
attr) AS DATA
FROM locations;
– JSON TO TABULAR DATA
– Server 10.6 the JSON_TABLE()
SELECT JSON_EXTRACT(attr, ‘$’) FROM locations;
SELECT l.name, d.food_type, d.menu
FROM locations AS l,
JSON_TABLE( l.attr,
‘$’ COLUMNS(
food_type VARCHAR(25) PATH ‘$.foodType’,
menu VARCHAR(200) PATH ‘$.menu’
)
) AS d
WHERE id=1;
ALTER TABLE locations ADD CONSTRAINT check_attr
CHECK(
type != ‘S’ OR (type = ‘S’ AND
JSON_TYPE(JSON_QUERY(attr, ‘$.details’)) = ‘OBJECT’ AND
JSON_TYPE(JSON_QUERY(attr, ‘$.details.events’)) = ‘ARRAY’ AND
JSON_TYPE(JSON_VALUE(attr, ‘$.details.yearOpened’)) = ‘INTEGER’ AND
JSON_TYPE(JSON_VALUE(attr, ‘$.details.capacity’)) = ‘INTEGER’ AND
JSON_EXISTS(attr, ‘$.details.yearOpened’) = 1 AND
JSON_EXISTS(attr, ‘$.details.capacity’) = 1 AND
JSON_LENGTH(JSON_QUERY(attr, ‘$.details.events’)) > 0));
DROP TABLE locations;
—
- jsonpath-expressions: https://mariadb.com/kb/en/jsonpath-expressions/
- Json type tutorials : Using-json-in-mariadb



















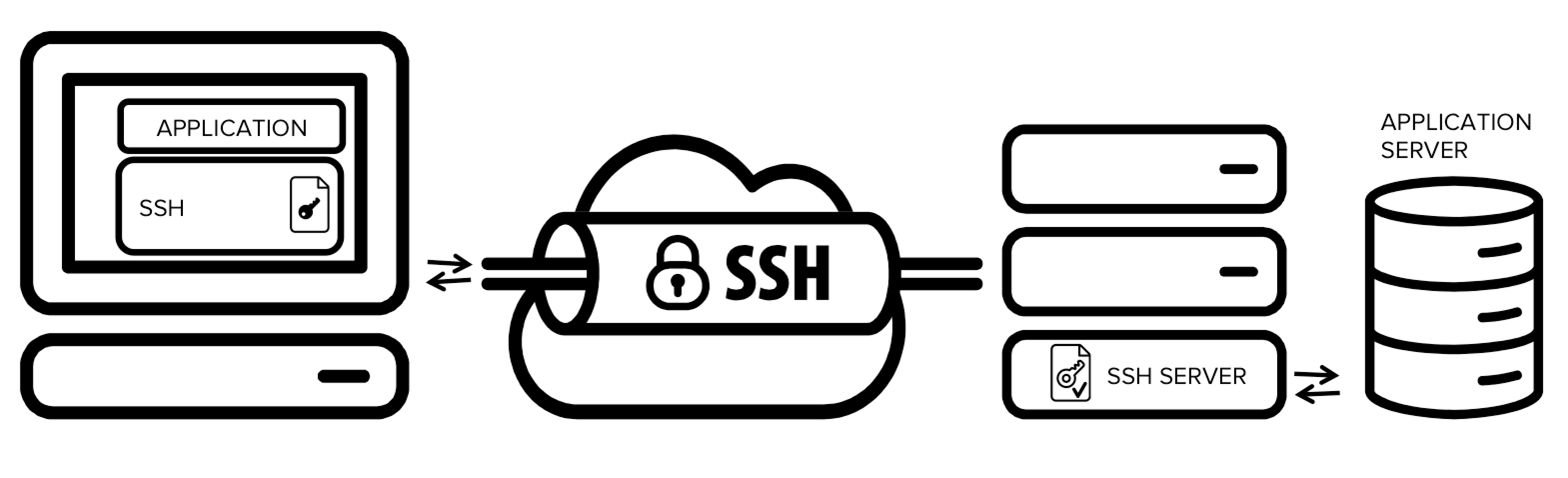 링크
링크