Tmux 시리즈:
- Tmux Start (202605)
- Tmux Cheatsheet (202605)
- Tmux Plugins (202605)
이 내용은 tmux 2.x, 3.x 에서 사용 가능하다.
2026-05-29: 내용 문맥 조정, 설치 부분 삭제.
- OLD Tmux Start(20170504)
2017-07-10: tmux-continum 추가
Tmux는 terminal multiplexer로 서버에 여러 프로그램을 세션에 저장하고, 다른 작업 혹은 연결을 끊었다 다시 접속해서 세션을 열어 작업을 이어갈 수 있다.

[그림. Tmux 실행 모습 (tmux.github.io)]
설치 관련 (OLD machines)
최신 리눅스는 대부분 내장으로 설치된 듯 하다: WSL, Ubuntu 24.04/26.04 …
- Ubuntu 14.04, Raspbian Jessie, Armbian 등에서 tmux가 1.8, 1.9 버전이 제공
- Ubuntu 15, 16 Xenivior 버전은 Tmux 2.1
- Old 버전 Ubuntu 14.04, Raspbian 등에서 tmux가 1.8, 1.9 버전이 제공되는데 package manager 같은 기능을 사용할 수 없다. 소스로 빌드해서 사용할 수 있다.
- Ubuntu 14.04 desktop, orangepi plus, raspberry pi jessie 초기 버전은 빌드 필요
시작
tmux 명령으로 시작할 수 있다.
tmux 를 시작하면 하나의 세션에 하나의 윈도우가 만들어 진다.
1 | tmux # 세션을 시작하고 참가한다. |
세션에 참가하면 하나 혹은 그 이상의 윈도우에서 Pane을 배치해 사용할 수 있다.

[그림. Tmux window layout]
세션 연결
세션은 하나 혹은 그 이상 만들고 attach 명령으로 세션에 참가할 수 있다.
1 | tmux new -s foo # 세션 foo를 시작 |
터미널에서 세션에 참가하려면 attach 명령과 대상 세션을 지정해 준다. 대상 세션은 tmux ls 명령에 표시되는 세션번호 혹은 세션이름을 지정한다.
1 | tmux attach |
세션을 완전히 종료 시키려면, tmux 세션에서 명령모드 C-: 에서 kill-session 명령을 실행한다.
혹은 다른 터미널에서 세션번호 혹은 세션 이름으로 종료한다.
1 | tmux kill-session -t 3 # 세션번호 3을 종료한다. |
Control와 Meta key
Tmux 세션 시작후 Prefix key 를 통해 세션, 윈도우와 tmux 내장 명령을 실행할 수 있다.
즉, Prefix key로 Session, Window, Pane 관련 명령을 키로 조합해 사용한다.
기본 Prefix key는 Control+b key고 옵션으로 사용하는 Meta key는 Alt 키 이다.
여기서 Prefix key는 C와 조합으로 표기하고, Meta key인 Alt는 M으로 표기한다.
윈도우 명령 control, meta 키 조합과 병행해 윈도우에서 명령모드를 사용할 수 있다.
명령모드는 C-: 키로 시작하고, 명령모드에서 명령 자동 완성 이 지원된다.

[그림. Window command mode]
Pane 다루기
윈도우는 수직/수평으로 구획을 나눌수 있다. C-“ 키로 현재 Pane 아래에 수평으로 새 Pane을 나눈다. 그리고 **C-%**키로 수직으로 새 Pane을 나눌 수 있다.

[그림. Tmux Window Pane]
- C-q : pane 번호를 표시하고 번호를 눌러서 이동
- C-o : pane을 순서대로 이동
- C-방향키 : 해당 방향으로 이동
- C-M-방향키 : 해당 방향으로 크기 조절
- C-M-1~5 : 몇 가지 미리 설정된 레이아웃을 고를 수 있고, prefix space로 이 레이아웃을 순서대로 - 돌아가며 선택 가능
- C-z : 특정화면만 확대하기 다시 예전 Panes상태로 돌아오기
Pane을 지우려면 C-x 키로 종료 혹은 터미널에서 exit로 터미널을 종료한다
Window 다루기
윈도우는 명령모드에서 new-window 혹은 C-c 키로 새 윈도우를 추가할 수 있다.
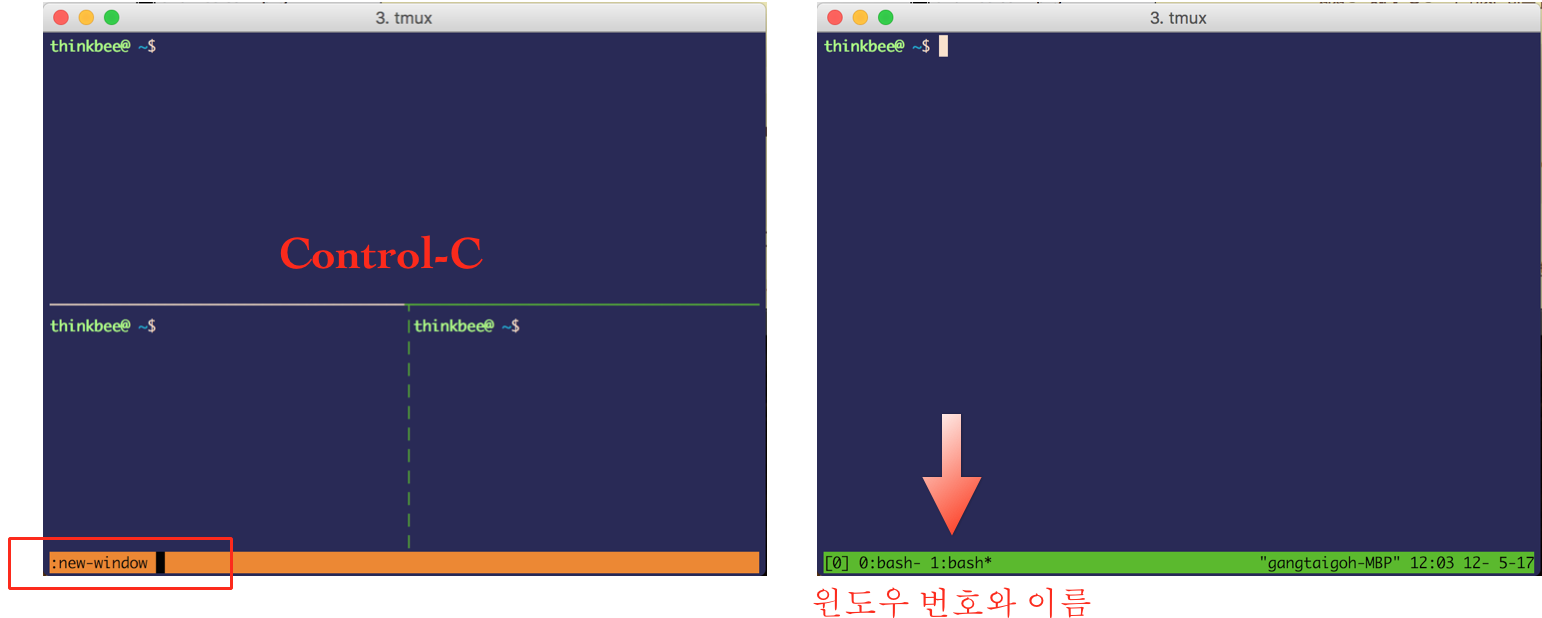
[그림. new Window ]
윈도우 목록은 C-w로 목록을 표시, 방향키로 윈도우 선택해 이동할 수 있다.
또한 윈도우 번호에 따라 단축키 C-0,1,2…9를 사용해 윈도우 사이의 이동 가능.
- C-n, C-p : 다음 윈도우, 이전 윈도우로 이동
- C-l : 직전 사용하던 윈도우로 이동
- C-w : 윈도우 리스트를 띄우고 선택
- C-, : 윈도우 이름 바꾸기
세션 사용중에 세션을 빠져 나오려면 C-d 로 Tmux 를 detach 할 수 있다.
detach는 명령모드 C-:에서 detach 명령을 사용할 수 있다.
복사와 스크롤
Tmux 터미널 화면 버퍼는 한 화면만 표시가 가능하다.
이전 화면 내용을 보려면 스크롤 기능을 켜야 한다. C+[ 로 스크롤 켜면, 우측상단에 페이지 표시가 나타난다.
키보드 방향키나 Page Up/Down키로 스크롤이 가능하다.
설정 사용
Tmux 의 환경 파일은 tmux 설정을 위힌 default 파일이 존재하지 않는다. 그래서 사용자가 별도의 설정파일에 작성해서 사용하면 된다.
보통 사용자 홈디렉토리에 .tmux.conf 파일에 tmux에 대한 설정을 명시할 수 있다.
설정 탑재:
- tmux 세션 사용중, 설정 재탑재
현재 사용중인 세션에서 C+r 로 재탑재가 가능하다.
1 | C-r : 설정 파일을 새로고침합니다 |
- tmux source 사용
변경한 설정을 적용하려면 터미널에서 다음 명령을 사용한다.
1 | tmux source ~/.tmux.conf |
현재 설정 추출과 백업:
tmux 기본 설정을 백업 혹은 확인하려면 tmux show 명령으로 확인이 가능하다.
1 | tmux show -g |
현재 tmux에 설정된 값을 백업:
1 | tmux show -g | sed 's/^/set-option -g /' > ~/.tmux/tmux.current.conf |
Prefix key 조합 변경
Prefix 키를 Control + a 키 조합이 편하다. 설정파일에 키 조합을 지정한다.
1 | Control+a에 'prefix' 연결 |
설정을 다시 탑재하면 prefix는 C-a 로 재배치된다.
관리자들은 Capslock키를 Control 키도 선호한다.
참고
- OLD Tmux 시작
- OLD Tmux cheatsheet
