Image Segmentation:
https://storm.genie.stanford.edu/article/image-segmentation%0A-410216
이미지 분할(Image Sementation)의 주요 목적은 특정 영역 분리와 식별이다. 이미지 안의 여러 사물에서 관심 영역을 분리함으로써 사용자는 관련 정보를 추출하고 해당 영역을 정량적으로 분석할 수 있게 된다.
이미지 분할 (Image Sementation) 이란
이미지 분할 (Segmentation) 은 이미지 안의 개체를 분석에 필요한 대상을 다중 분할 또는 영역으로 나누는데 관련한 컴퓨터 비전과 인공지능의 중대한 기술이다.
이미지에 있는 뚜렷한 객체 또는 특성을 식별하고 분리하기 위해서 세그멘테이션은 의료 이미지에서 자동차까지 다양한 응용분야에서 성장했다.
이미지의 공간적 구조와 구성에 대한 자세한 정보를 제공하는 기능은 컴퓨터 비전에서 주목할 만한 분야로, 의료, 감시 및 엔터테인먼트 등의 산업 전반에 사용되고 있다.
이미지 분할의 진화는 1950년대와 1960년대의 초기 방법에서 시작하여 현대 기술의 토대를 마련한 몇 가지 중요한 단계를 거쳐 추적할 수 있다. [1][2]
이 분야는 1990년대 디지털 혁명 동안 디지털 이미지와 계산 능력의 증가로 인해 상당한 발전을 이루었다. 이는 2000년대와 2010년대에 정점을 이루었고, 특히 합성곱 신경망(CNN)과 같은 딥 러닝의 출현으로 이미지 분할 기능이 변형되어 이미지 내의 복잡한 패턴과 객체를 인식하는 데 있어 전례 없는 정확성과 효율성을 이루었다. [2] [3]
기술의 발전에 따라 이미지 분할은 감시와 얼굴 인식에서 윤리적 우려, 프라이버시 등의 의문이 제기되고 또한 데이터 가변성, 폐색 및 고급 알고리즘의 높은 계산 요구 사항과 같은 문제는 효과적인 구현에 대한 상당한 장애물로 계속 남아 있다.[1][3]
헬름홀츠의 무의식적 추론 이론
19세기의 헤르만 폰 헬름홀츠는 우리가 보는 것은 단순히 망막에 맺힌 이미지가 아니라 뇌가 경험과 지식을 바탕으로 재구성한 결과라는 것이이다. 시각이론은 컴퓨터 비전 시스템이 상황 정보, 사전 지식, 추론 능력 등을 활용해야 함을 시사했습니다. [A4]
초기 1950년대~1960년대
1950년대에서 1960년대는 컴퓨터 비전과 인공 지능(AI)의 시작 단계였다. AI가 학문 분야로 공식적으로 확립된 시기였으며, 특히 존 매카시와 마빈 민스키와 같은 선구자들이 조직한 1956년 다트머스 컨퍼런스가 주요 성과였다. [1]
AI 초기 연구는 기계에 시각 데이터를 “보고” 해석하는 능력을 부여하는 데 중점을 두었으며, 이는 이미지 처리 및 세분화 기술의 미래 발전을 위한 토대를 마련했습니다.
디지털 이미지 처리는 1960년대에 이미지를 디지털 형식으로 변환하여 컴퓨터 처리가 가능해졌다. 1963년 MIT의 Larry Roberts는 2차원 이미지에서 3차원 장면을 재구성하는 알고리즘을 도입하여 이 분야를 발전시켰습니다. 이러한 발전으로 컴퓨터는 이미지 데이터를 분석하고 해석할 수 있게 되었습니다. [A3]
James Cooley와 John Tukey가 1965년에 개발한 고속 퓨리에 변환(FFT) 알고리즘 개발하였고, FFT는 이미지와 같은 신호를 공간 영역에서 주파수 영역으로 변환하는 이산 퓨리에 변환(DFT)을 효율적으로 계산한다. 컴퓨터 비전에서 FFT를 활용하여 이미지 필터링, 노이즈 감소, 특징 추출과 같은 필수 작업을 수행할 수 있다.
성장과 도전 1980년대
DARPA 등 지원으로 연구자들은 이미지 분할의 기본 구성 요소인 객체 인식 및 장면 이해와 관련된 복잡한 과제를 해결하기 시작다. 그러나 당시 기술은 제한적이었으며 많은 시스템이 조명, 크기 및 관점의 변화로 인해 객체를 정확하게 식별하는 데 어려움을 겪었습니다.[1]
디지털 혁명 1990년대
1990년대는 디지털 카메라의 등장과 인터넷의 급속한 확장을 특징으로 하는 디지털 혁명으로 시각 데이터의 가용성이 기하급수적으로 증가하면서 컴퓨터 비전에서 디지털 이미지의 알고리즘을 훈련하기 위한 풍부한 데이터 세트를 제공되며 이미지 분할 방법론의 역량을 향상시켰다. 특히 객체 인식 및 특징 추출 기술에 대한 추가 연구 개발을 촉진했습니다. [2]
빅데이터와 딥러닝의 부상(2000년대-2010년대)
2000년대는 빅데이터와 강력한 컴퓨팅 리소스에 의해 합성곱 신경망(CNN)의 도입으로 이미지 처리의 풍경을 변화시켜 시각적 인식 작업의 속도와 정확도를 크게 향상시켰습니다.[ 2 ]
2010년대에는 딥 러닝 혁명이 이미지 분할 기술을 더욱 발전시키며 얼굴 인식 시스템 및 자율 주행차를 포함한 다양한 분야에서 이미지 분할이 실질적으로 적용되었다.
2012년에 CNN 기반 접근 방식이 ImageNet Large Scale Visual Recognition Challenge(ILSVRC)에서 놀라운 성공을 거두면서 이미지 인식 작업에서 딥 러닝의 혁신적 힘을 강조하면서 분수령이 발생했습니다. [1]
현대적 이슈와 미래 방향
이미지 분할 기술이 발전함에 따라 특히 감시 및 얼굴 인식 응용 분야의 맥락에서 윤리 및 개인 정보 보호 문제도 제기되었습니다.[ 1 ]
이러한 기술의 의미를 둘러싼 지속적인 논쟁은 기술 발전과 개인의 권리를 균형 있게 유지하는 책임 있는 혁신의 필요성을 강조합니다. 앞으로 적대적 훈련 및 전이 학습을 포함한 새로운 방법의 지속적인 개발은 이미지 분할 연구와 실제 세계 응용 분야에 대한 흥미로운 미래를 예고합니다.[ 1 ] [ 3 ]
방법
방법은 전통적인 기술과 딥 러닝 프레임워크를 사용하는 기술로 크게 분류할 수 있습니다.
영역 확장 Region-growing method
영역 확장 방법은 영역 내의 이웃 픽셀이 유사한 강도 값을 공유해서 시드 픽셀을 선택하고 유사성 기준을 충족하는 이웃 픽셀을 추가하여 영역을 확장하는 방법이다.
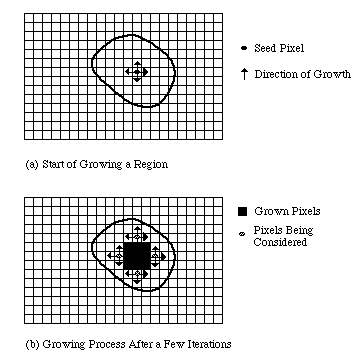
시드 영역 확장(SRG) 기술은 미리 정해진 시드 포인트를 사용하여 강도 유사성에 따라 영역을 반복적으로 확장하는 반면, 시드되지 않은 영역 확장 방법은 단일 픽셀로 시작하여 임계값 비교에 따라 새로운 영역을 만듭니다. [4][5]
임계값 설정 Thresholding
임계값 설정은 임계값을 사용하여 픽셀을 여러 클래스로 구분하는 기본 기술로, 객체 감지 및 특징 추출과 같은 작업을 가능하게 합니다.

간단한 임계값 설정은 전역 임계값을 기반으로 각 픽셀에 이진 값을 할당하지만 다양한 조명 조건에서 어려움을 겪을 수 있습니다. 적응형 임계값 설정은 로컬 특성에 따라 각 픽셀의 임계값을 조정하여 복잡한 이미지의 분할을 개선합니다. [6]
Motion-based Segmentation
동작 기반 분할 기술은 일련의 이미지에서 동작 정보를 얻기 위해서 프레임 간의 차이점을 분석해서 움직이는 객체를 정적 배경에서 분리할 수 있습니다.

대화형 분할은 로봇 시스템을 활용하여 효과적인 분할에 필요한 동작 신호를 생성함으로써 이를 더욱 향상시킵니다.[7]
딥러닝 U-Net 및 변형
u-net은 이미지를 빠르고 정확하게 분할하기 위한 합성곱 네트워크 아키텍처입니다. 원래 생물의학 이미지 분할을 위해 설계되어 이 분야의 기초 아키텍처가 되었다. 지금까지 전자 현미경 스택의 신경 구조 분할을 위한 ISBI 챌린지 에서 이전의 가장 좋은 방법(슬라이딩 윈도우 합성곱 네트워크)보다 더 나은 성과를 보였습니다. [A]
ISBI 2015에서 바이트윙 방사선 촬영에서 우식의 컴퓨터 자동 감지를 위한 그랜드 챌린지에서 우승했으며 , ISBI 2015에서 두 가지 가장 어려운 투과광 현미경 범주(위상차 및 DIC 현미경)에서 세포 추적 챌린지 에서 큰 차이로 우승했습니다 (또한 당사의 발표 참조 ).[A2]
U-Net 는 스킵 연결을 통해 공간 정보를 보존하면서 컨텍스트를 캡처하는 인코더-디코더 구조로 구성됩니다.
 - https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
- https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
U-Net 모델의 변형 및 향상은 의료 이미지 분할 연구에서 널리 퍼져 있으며, 종종 다양한 애플리케이션에서 성능이 향상됩니다.[5][6]
딥러닝 3D-CNN 및 Transformer 아키텍처
최근 이미지 분할의 발전으로 3D-CNN 및 Transformer 아키텍처를 기반으로 하는 모델은 체적 데이터 처리에서 강력한 성능을 보여주지만 일반적으로 상당한 계산 리소스가 필요합니다. 반면 Transformer 모델은 분할 도메인 내에서 혁신할 수 있는 잠재력으로 주목을 받고 있으며 복잡한 데이터 세트를 처리하는 새로운 접근 방식을 제공합니다. [8]
결합된 분류기 (Combind Classifier) 접근 방식
여러 분류기의 통합은 세분화 정확도를 향상시키기 위해 제안되었습니다. 이 방법은 다양한 분류 알고리즘의 강점을 활용하여 인식 및 세분화 품질을 개선합니다.
의사결정 융합 전략의 계층 구조
 - A Survey of Decision Fusion and Feature Fusion Strategies for Pattern Classification
- A Survey of Decision Fusion and Feature Fusion Strategies for Pattern Classification
다양한 분류기의 결과를 결합함으로써 세분화 결과는 입력 데이터의 노이즈 및 변동성에 대해 더 큰 견고성을 얻을 수 있습니다. [7][5]
평가지표
주요 지표에는 정밀도, 재현율, 정확도, F1 점수, Intersection over Union(IoU), Boundary F1 점수 등이 있습니다. 이 항목 외에도,
- 알고리즘 학습과 실행에 필요한 시간을 모두 포함하는 분할 방법의 계산 효율성을 평가하는 것이 필수적입니다.[7]
- 세분화 방법은 성능에 대한 포괄적인 평가를 보장하기 위해 정밀도, 재현율, 정확도 및 효율성 요소를 기준으로 비교해야 합니다.[7]
- 또한 연구자들은 전문가 지식을 주석 품질에 통합하고 Dice 계수와 같은 기존 방법을 넘어서는 새로운 지표를 개발하는 것과 같이 세분화 정확도의 더 복잡한 측면을 포착하기 위해 평가 지표를 지속적으로 개선하고 있습니다.[11]
도전 과제
이미지 분할은 실제 시나리오에서 효과성과 적용성을 방해하는 다양한 과제에 계속 직면하고 있습니다. 이러한 과제는 데이터 가변성과 관련된 문제부터 분할 알고리즘의 계산적 요구 사항까지 다양합니다.
Partial occlusion
이미지에서 물체의 부분적 폐색 현상이다. 여러 프레임으로 이루어진 이미지에서 장애물로 인해 물체의 일부만 보니는 현상이다.

- A Novel Particle Filter Implementation for a Multiple-Vehicle Detection and Tracking System Using Tail Light Segmentation
이는 명확한 경계를 정의하는 작업을 복잡하게 만들어 크기, 모양 및 특징 측정에 오류가 발생하는 경우가 많습니다.[6]
여러 개체 포함시 임계값 조정 문제
또한 이미지에 다양한 모양, 크기 및 강도를 가진 여러 개체 유형을 포함하는 경우 다양한 개체에 대한 임계값을 조정하는 것이 복잡할 수 있으므로 상당한 어려움을 나타냅니다.[6]
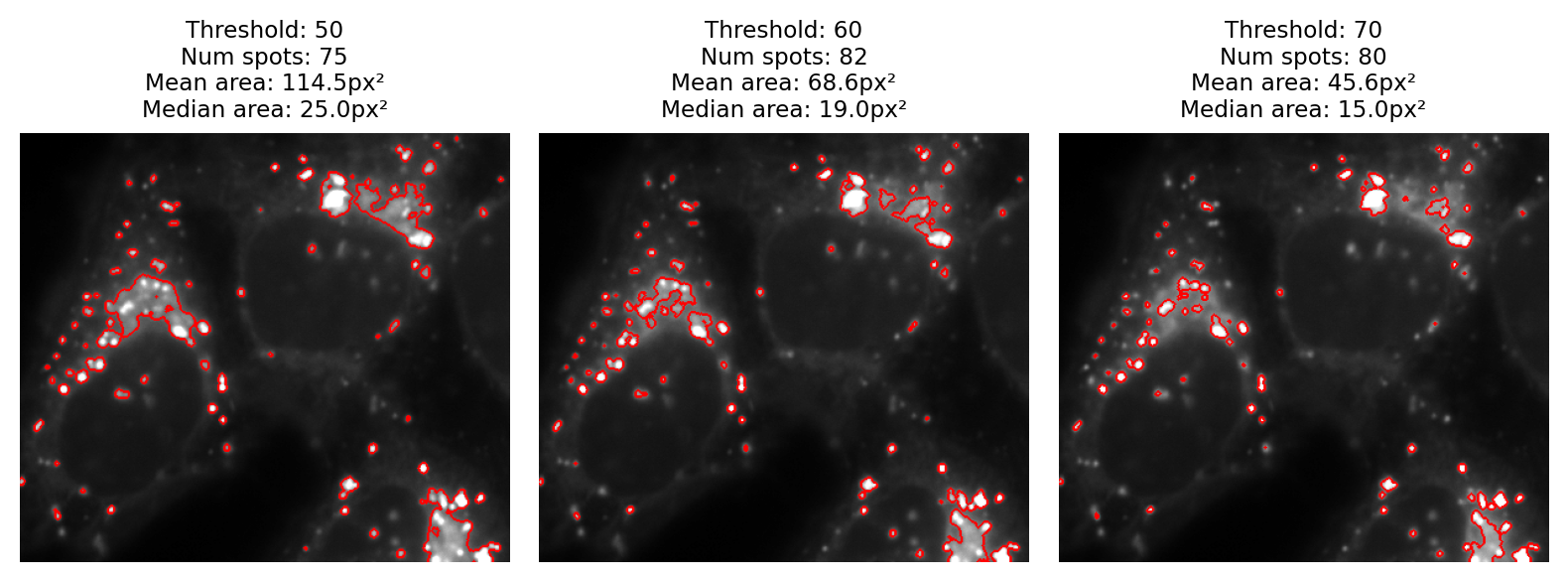 - https://bioimagebook.github.io/chapters/2-processing/3-thresholding/thresholding.html
- https://bioimagebook.github.io/chapters/2-processing/3-thresholding/thresholding.html
조명 및 컨텍스트 가변성
다양한 조명 조건도 효과적인 분할에 상당한 어려움을 줍니다. 고르지 않거나 균일하지 않은 조명에서 촬영한 이미지는 물체가 배경과 효과적으로 분리되지 않을 수 있으므로 부정확할 수 있습니다. [6]
 - A Low-Light Image Enhancement Method Based on Image Degradation Model and Pure Pixel Ratio Prior
- A Low-Light Image Enhancement Method Based on Image Degradation Model and Pure Pixel Ratio Prior
또한 이미지 내에서 점진적인 강도 전환이 존재하면 기존 방법은 일반적으로 잘 정의된 모서리에 최적화되어 있기 때문에 정확한 분할을 달성하기 어려울 수 있습니다.[6]
높은 계산 능력
또 다른 중요한 장애물은 많은 고급 세분화 기술, 특히 훈련 단계에서 필요한 높은 연산 능력입니다. 이러한 높은 연산 오버헤드는 빠른 응답이 중요한 실시간 처리 시나리오에서 특정 방법의 적용성을 제한할 수 있습니다.[ 9 ]
모델 가지치기, 양자화 및 GPU나 TPU와 같은 특수 하드웨어 가속기 활용과 같은 기술은 이러한 제한을 완화하는 데 도움이 될 수 있지만 상당한 리소스에 대한 필요성은 여전히 장애물로 남아 있습니다.[ 9 ]
AI 윤리 고려
투명하고 윤리적이며 책임감 있는 AI 구현은 환자의 신뢰와 안전을 유지하는 데 매우 중요합니다.
데이터 프라이버시: AI 모델 훈련에는 대량의 환자 데이터가 필요하며, 이러한 데이터는 개인의 민감한 건강 정보를 포함하고 있습니다. 따라서 데이터 프라이버시를 보호하는 것은 매우 중요하며, 데이터 익명화, 접근 제어, 보안 강화 등의 조치가 필요합니다. [19]
훈련 데이터의 편향: AI 모델은 훈련 데이터의 편향을 반영할 수 있으며, 이는 특정 인종, 성별, 사회경제적 배경의 환자에게 불공정한 결과를 초래할 수 있습니다. 따라서 다양하고 대표적인 데이터 세트를 사용하여 훈련 데이터의 편향을 최소화하고, 공정성을 확보하는 것이 중요합니다. [19]
AI 기반 결정의 해석 가능성: 심층 학습 모델은 종종 “블랙 박스”로 여겨지며, 의사 결정 과정을 이해하기 어려울 수 있습니다. 의료 분야에서는 의사가 AI 모델의 결정을 이해하고 신뢰할 수 있어야 하므로, 설명 가능한 AI(XAI) 기술 개발이 중요합니다. 설명 가능한 AI는 AI 모델의 의사 결정 과정을 투명하게 공개하고, 의료 전문가가 AI 모델의 판단 근거를 이해하고 검증할 수 있도록 지원합니다. [19]
미래 방향
이미지 분할 분야의 개선 및 혁신 분야에 초점을 맞춰 이미지 분할의 잠재적인 미래 방향을 논의합니다.
딥러닝 통합
미래 연구의 유망한 방향은 세분화 성능을 향상시키기 위해 다양한 딥 러닝 모델을 결합하는 것입니다. 신경망 아키텍처의 지속적인 발전은 하이브리드 모델이 여러 접근 방식의 강점을 활용하여 더 우수한 결과를 제공할 수 있음을 시사합니다. 이러한 통합은 다양한 영상 조건 및 모달리티에 더 적합한 보다 견고하고 일반화 가능한 세분화 알고리즘의 개발로 이어질 수 있습니다.[17][8]
크로스 도메인 적응
교차 도메인 세분화는 여전히 중요한 과제로 남아 있으며, 특히 영상 기술의 변화가 성능에 상당한 영향을 미칠 수 있는 의료 영상 분야에서 그렇습니다. 향후 연구에서는 도메인 이동의 영향을 완화하고 다양한 데이터 세트에서 세분화 모델의 효능을 개선하는 것을 목표로 하는 새로운 도메인 적응 기술을 탐색할 수 있습니다. [8]
연구자들은 보다 풍부한 맥락적 이해를 제공하고 향상된 세분화 정확도로 이어질 수 있는 다중 모달 이미징 데이터의 통합을 조사하도록 권장됩니다.[18]
실시간 처리
실시간 처리 기능에 대한 수요는 특히 자율 주행차 및 의료 진단과 같은 애플리케이션에서 증가하고 있습니다. 미래의 이미지 분할 프레임워크는 정확도를 손상시키지 않으면서 실시간 실행을 위한 알고리즘 최적화에 집중해야 합니다 이를 위해서는 실시간 분석의 높은 요구 사항을 처리할 수 있는 보다 효율적인 계산 모델을 개발해야 합니다. [1]
학제간 시너지(Synergy with Other AI Domain)
이미지 분할과 자연어 처리(NLP) 및 증강 현실과 같은 다른 AI 기술의 교차점은 혁신을 위한 비옥한 토양을 제공합니다. 시스템이 시각 데이터와 인간 언어를 모두 해석하고 이해할 수 있도록 함으로써 연구자는 사용자 상호 작용 및 의사 결정 프로세스를 향상시키는 보다 포괄적인 AI 애플리케이션을 만들 수 있습니다. [1]
설명 가능한 (Explainable) AI
AI가 의료 분야에 계속 침투함에 따라 설명 가능한 AI에 대한 필요성이 가장 중요해졌습니다. 세분화 기술의 미래 발전은 투명성을 우선시해야 하며, 의료 전문가가 진단 프로세스를 주도하는 알고리즘을 이해하고 신뢰할 수 있도록 해야 합니다. 설명 가능성에 대한 이러한 초점은 의학과 같은 민감한 분야에서 AI 기술을 책임감 있게 배포하는 데 매우 중요할 것입니다. [19]
참고
[4] 이미지 분할 - 위키피디아, https://en.wikipedia.org/wiki/Image_segmentation
[5] 의미론적 이미지 분할의 최근 진전 - arXiv.org: https://arxiv.org/abs/1809.10198
[6] 이미지 처리에서의 이미지 임계값 설정 - Encord: https://encord.com/blog/image-thresholding-image-processing/
[7] …대한 이미지 분할 알고리즘의 성능 평가: https://www.academia.edu/88049601/미시적 이미지 데이터에 대한 이미지 분할 알고리즘의 성능 평가
[8] 뇌 의학적 분야에서 여러 영역의 과제를 해결하기 위한 접근법 탐구 : https://www.frontiersin.org/journals/neuroscience/articles/10.3389/fnins.2024.1401329/full
[11] 컴퓨터 비전에서의 이미지 분할 가이드: 모범 사례 - Encord : https://encord.com/blog/image-segmentation-for-computer-vision-best-practice-guide/
[17] An overview of intelligent image segmentation using active contour models: https://www.oaepublish.com/articles/ir.2023.02
[19] Medical Image Segmentation and Its Real-World Applications: https://medium.com/@jervisaldanha/medical-image-segmentation-and-its-real-world-applications-unet-and-beyond-9cd06eeebcb6
[A1] ISBI 2015, http://brainiac2.mit.edu/isbi_challenge/
[A2] http://lmb.informatik.uni-freiburg.de/people/ronneber/isbi2015/
[A3] “Machine Perception of Three-Dimensional Solids”, Larry Roberts, : https://bit.ly/3ZPSBHF
[A4] “The Dawn of Computer Vision:”, https://www.turingpost.com/p/cvhistory2

 그림 - google ai blog
그림 - google ai blog
 그림 - google ai blog: https://ai.googleblog.com/2020/02/open-images-v6-now-featuring-localized.html
그림 - google ai blog: https://ai.googleblog.com/2020/02/open-images-v6-now-featuring-localized.html
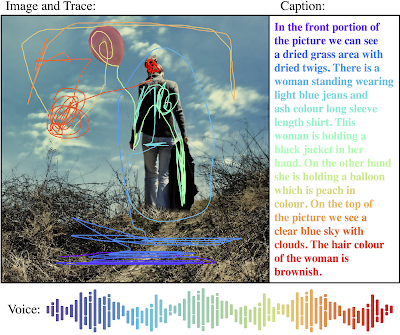
 그림 - https://paperswithcode.com/paper/visual-genome-connecting-language-and-vision/
그림 - https://paperswithcode.com/paper/visual-genome-connecting-language-and-vision/
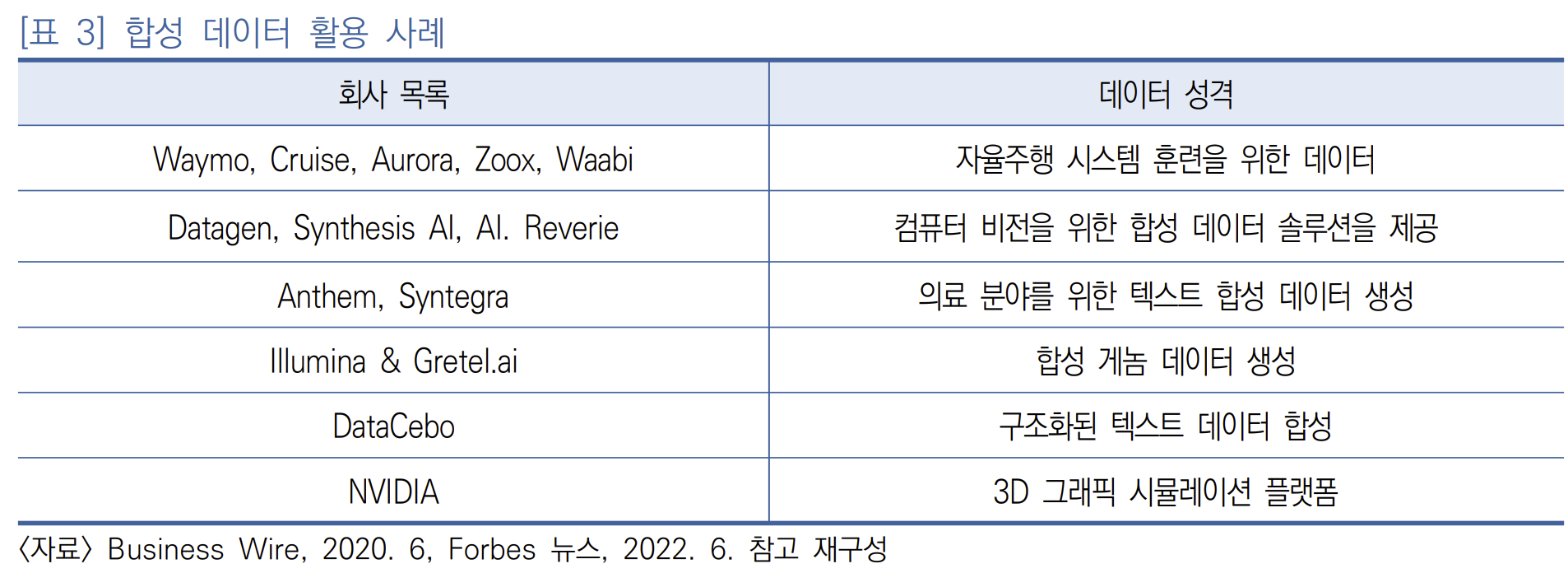
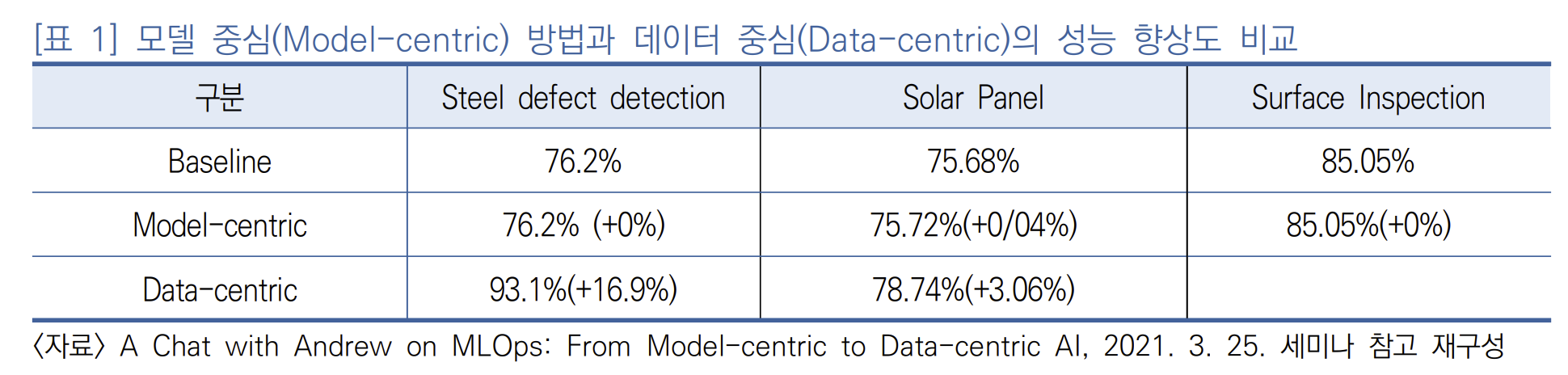
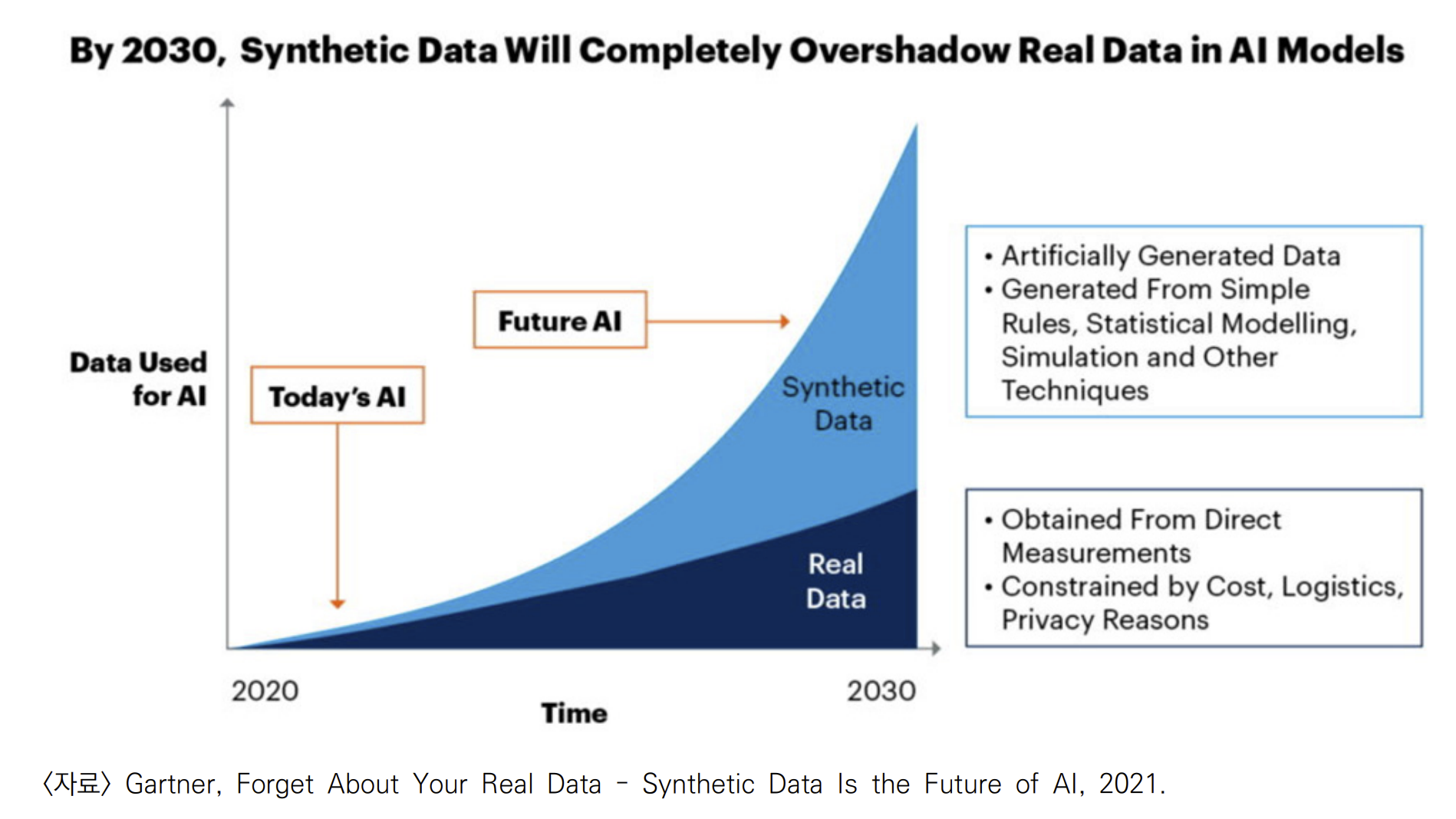
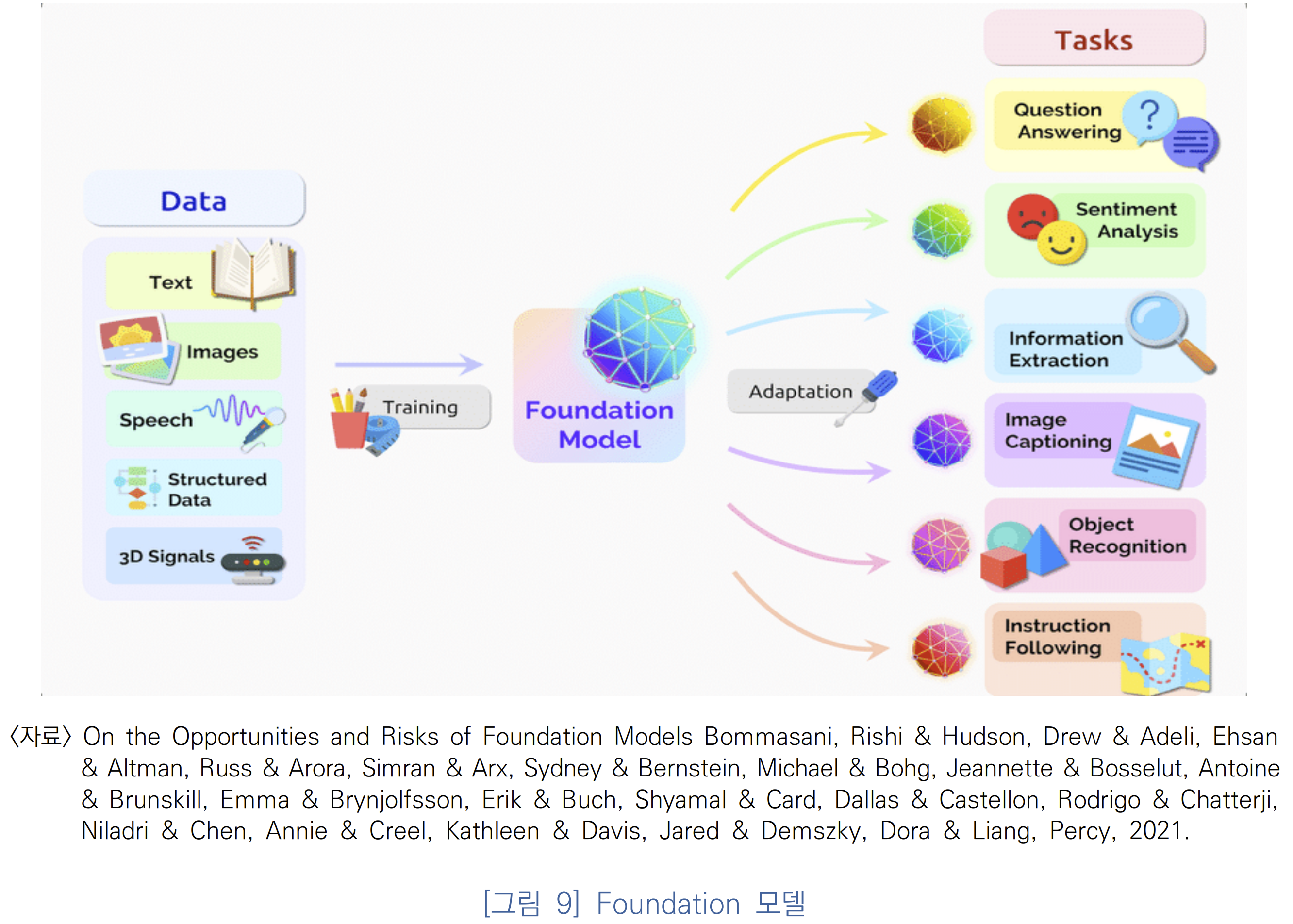
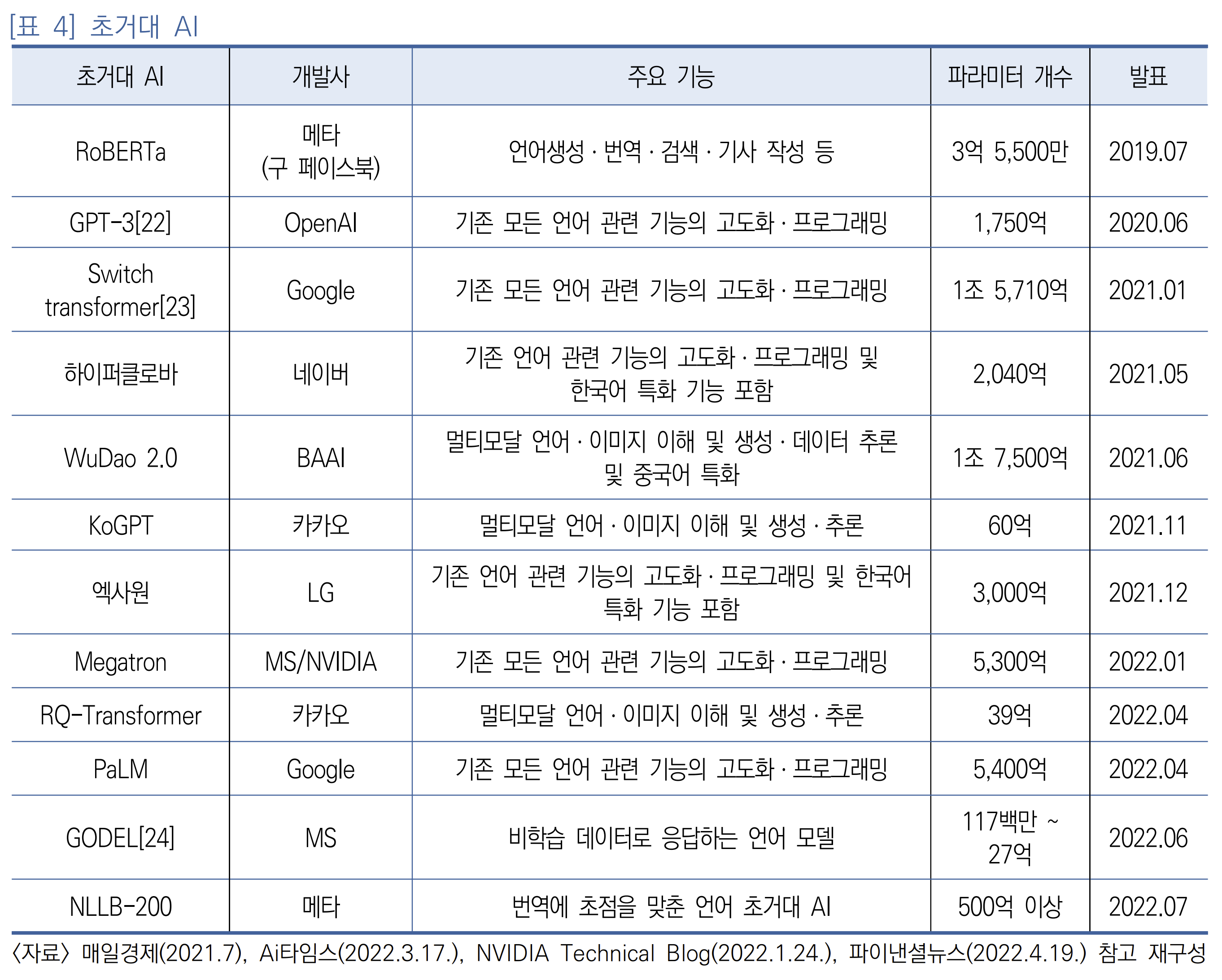
 그림 - https://www.microsoft.com/en-us/research/blog/godel-combining-goal-oriented-dialog-with-real-world-conversations/
그림 - https://www.microsoft.com/en-us/research/blog/godel-combining-goal-oriented-dialog-with-real-world-conversations/