$ pyenv doctor Cloning /home/USER/.pyenv/plugins/pyenv-doctor/bin/..... Installing python-pyenv-doctor... Installed python-pyenv-doctor to /tmp/pyenv-doctor.20250327094025.5063/prefix Congratulations! You are ready to build pythons!
기타
시스템에 빌드 도구가 설치되지 않으면 doctor 명령을 실행하면 다양한 에러를 낸다.
1 2 3 4 5 6 7
$ pyenv doctor ... ... configure: error: GNU readline is not installed. Problem(s) detected while checking system.
See https://github.com/pyenv/pyenv/wiki/Common-build-problems for known solutions.
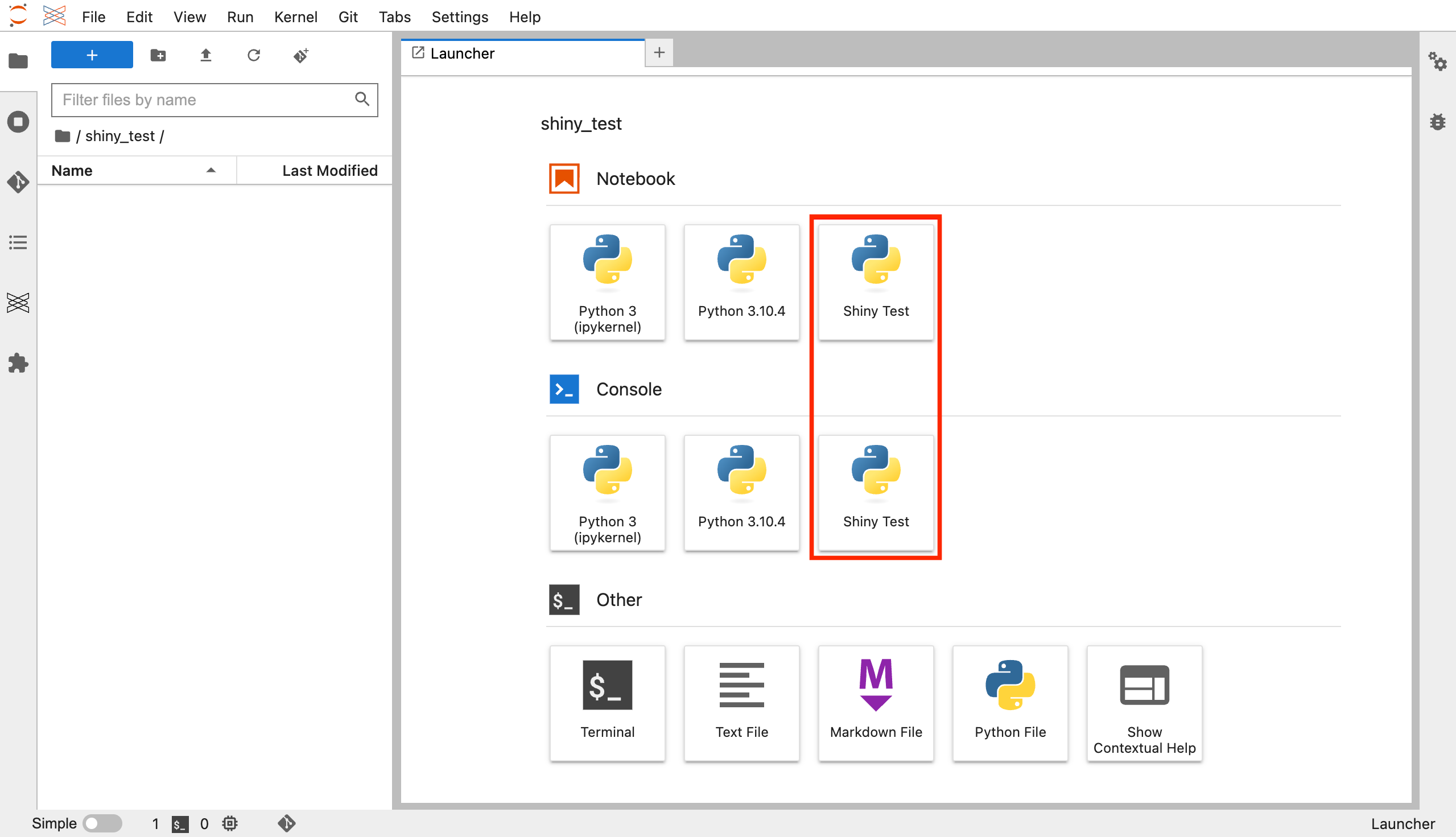
Jupyter 3.x 를 사용중에 Jupyter 4.0 출시를 했다고 해서 가상환경을 만들고 jupyterlab 4.0 을 설치했었다. 조금 더 UI 가 명확해 보이고 괜잖았는데 한글 입력시 글가가 깨져서 입력되거나 혹은 현재 편집중인 Cell 의 위치가 달라져 보이는 이상한 증상이 있어서 4.0 업그레이드 버전 사용을 안했는데 이유는 Node.js 버전 문제로 보인다.
Node.js 버전
기존에 jupyterlab 3.6 에서 Node.js 14 버전을 사용하고 있었다. Jupyterlab 4.x 버전의 주피터 확장 모듈 빌드도 문제가 없었는데 위에 언급한 이상한 현상이 발생해서 Jupyterlab 4.x 가상환경에서 Node.Js 버전을 18버전으로 업그레이후 후에는 문제없이 사용중이다.
이 코드는 소스로 쉘에서 실행하거나 Web 기반의 jupyterlab 에서 실행하면 아무 문제이 print 문이 잘 작동하고 출력 결과가 나온다.
1 2
>>> ! python mutiprocess1.py Hello multiproess
print 의 Multiprocessing 에서 문제는 링크 참고1 을 읽어보기를 권한다. 이 글에서는 테스트한 내용을 정리만 했다.
원인
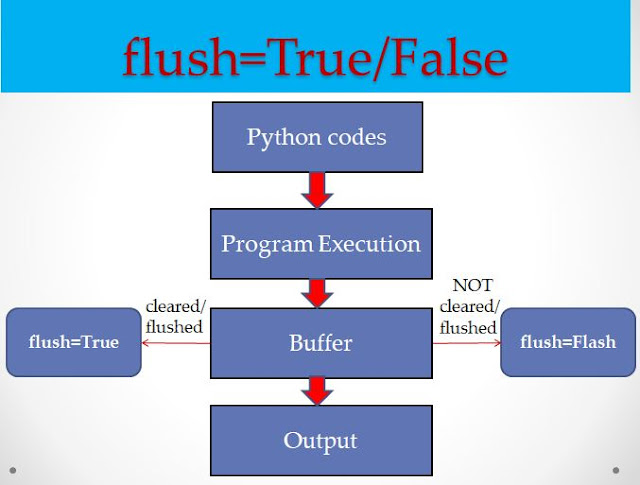
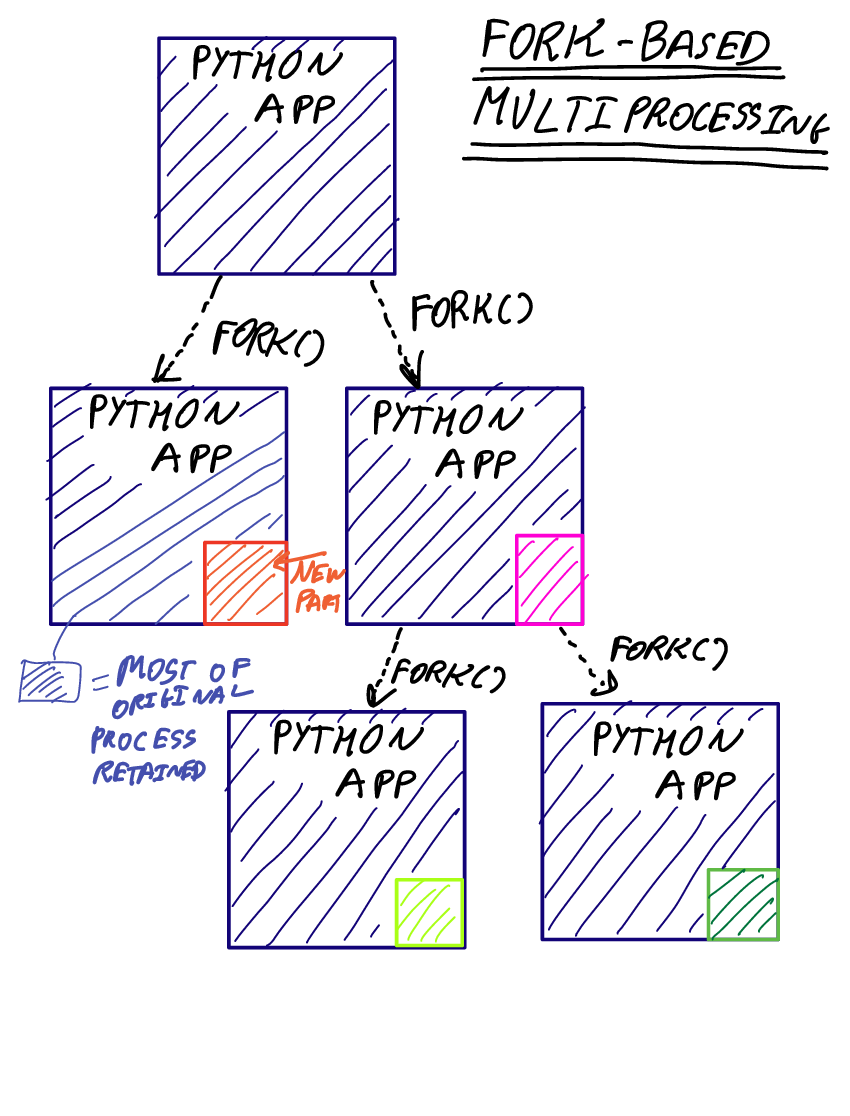
아래 링크 참고1 기사에서 설명을 자세히 하고 있다. 보통 파이썬에서 차일드 프로세스를 시작할 때는 'fork', 'spawn', 'forkserver' 방법이 있다고 한다. 그런데 spawn 으로 차일드 프로세스를 실행하면 std io 출력 버퍼가 자동으로 비워지지 않는다(print는 기본으로 flush가 되지 않는다). 그러다 보니 차일드 프로세스가 종료 하면서 자동으로 gabage collection에 의해 버퍼에 남아 있는 메시지가 사라지는 것이다.
해결 방법
메시지 버퍼가 사라지기 전에 flush 를 한다.
fork 기반의 프로세스를 생성한다.
1. flush 사용
메시지 버퍼가 사라지기 전에 flush 를 한다.
이를 해결하기 위해 모든 print 의 출력은 즉시 flush 되도록 flush=True 옵션을 사용할 수 있다고 한다.
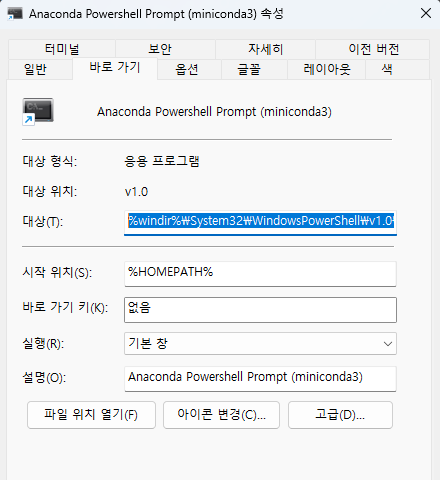
Anaconda / Miniconda 를 설치하고 윈도우즈에서 실행시 바로가기로 사용하는 방법을 정리했다. 모든 Commandline, Powershell 에서 conda 명령을 사용하려면 환경변수 PATH 에 지정을 해야 한다. 이 글에서는 바로가기를 사용하면 PATH 환경변수를 활용하지 않고도 쉽게 사용할 수 있다.
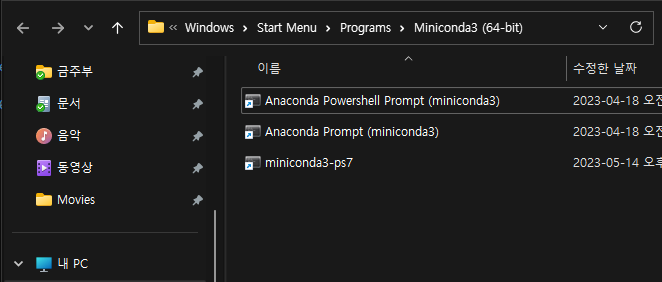
Anaconda/Miniconda 설치 프로그램으로 설치를 하면 바로가기를 만들어 준다. 여기서 힌트를 얻으면 된다.
바로가기 속성을 사용해 파워쉘로 conda 환경을 초기화 하기 위해서는 conda-hook.ps1 실행이 필요하다. 설치한 Anaconda 시작프로그램의 속성을 통해 알 수 있다. 보통 설치된 아래 위치에 있다.
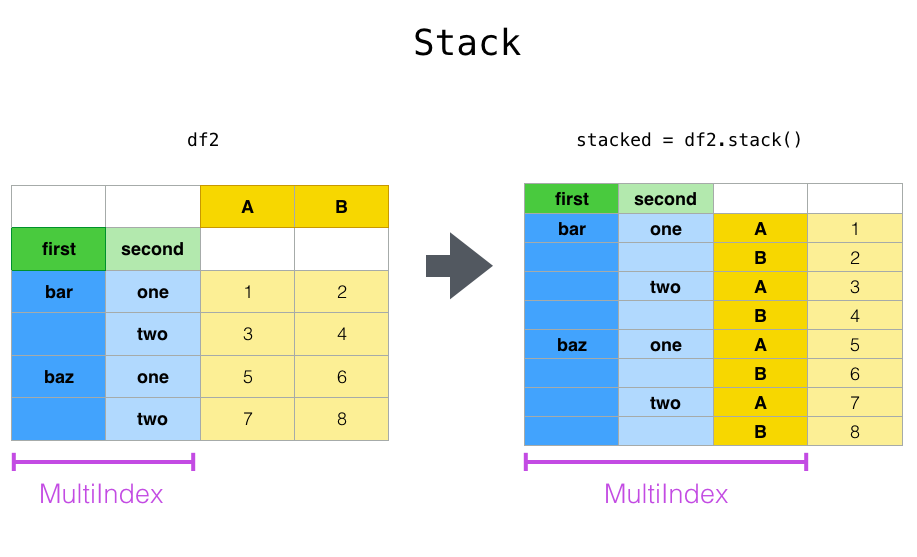
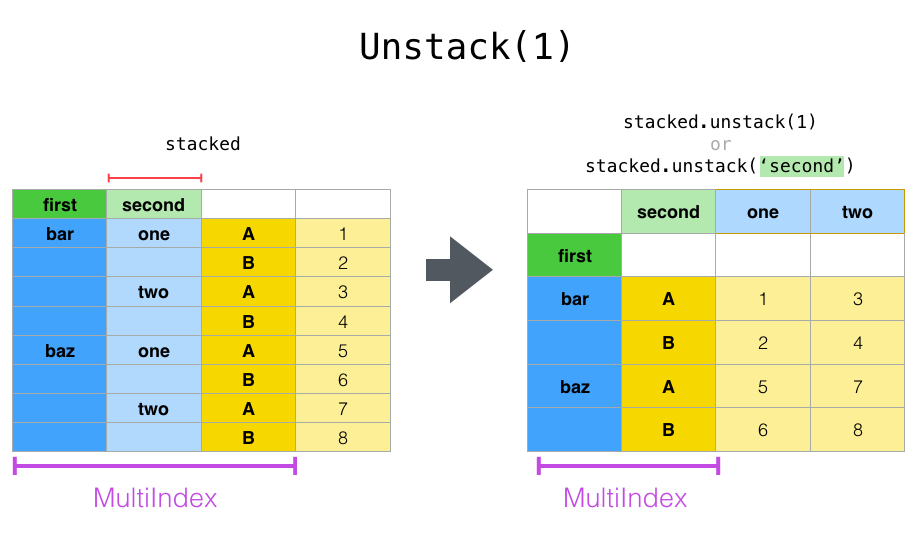
위 데이터는 stack()을 하면 A, B 컬럼이 MultiIndex 로 추가되며 A, B 컬럼 데이터 포인트가 배치된다.
1
df.stack()
first second
bar one A -1.301694
B -0.013259
two A -0.197846
B 0.879890
baz one A 0.718211
B -0.739434
two A -0.140217
B 0.071260
foo one A -1.142268
B -2.606413
two A 1.119145
B 0.109402
qux one A -0.504167
B -1.703280
two A 1.064976
B 1.011060
dtype: float64
1 2
df2 = df[:4] df2
A
B
first
second
bar
one
-1.301694
-0.013259
two
-0.197846
0.879890
baz
one
0.718211
-0.739434
two
-0.140217
0.071260
1 2
stacked = df2.stack() stacked
first second
bar one A -1.301694
B -0.013259
two A -0.197846
B 0.879890
baz one A 0.718211
B -0.739434
two A -0.140217
B 0.071260
dtype: float64


 그림>
그림>