$ pyenv doctor Cloning /home/USER/.pyenv/plugins/pyenv-doctor/bin/..... Installing python-pyenv-doctor... Installed python-pyenv-doctor to /tmp/pyenv-doctor.20250327094025.5063/prefix Congratulations! You are ready to build pythons!
기타
시스템에 빌드 도구가 설치되지 않으면 doctor 명령을 실행하면 다양한 에러를 낸다.
1 2 3 4 5 6 7
$ pyenv doctor ... ... configure: error: GNU readline is not installed. Problem(s) detected while checking system.
See https://github.com/pyenv/pyenv/wiki/Common-build-problems for known solutions.
micromamba 는 mamba의 소규모 버전으로 독립적 실행 파일이다. 다만 mamba 와 micromamba는 환경 구성이 좀 다르다. micromamba는 mamba와 다르게 MAMBA_ROOT_PREFIX 환경 변수를 기준으로 패키지 관리가 시작되고 환경이 생성된다.
Downloading micromamba from https://github.com/mamba-org/micromamba-releases/releases/latest/download/micromamba-win-64 % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 00000000--:--:----:--:----:--:--0 00000000--:--:----:--:----:--:--0 1009280k 1009280k 003355k 00:00:020:00:02--:--:--10.8M
Installing micromamba to C:\Users\student\AppData\Local\micromamba
Adding C:\Users\student\AppData\Local\micromamba\micromamba.exe to PATH
Do you want to initialize micromamba for the shell activate command? (Y/n): y Enter the path to the micromamba prefix (default: C:\Users\student\micromamba): Initializing micromamba in C:\Users\student\micromamba C:\Users\student\AppData\Local\micromamba\micromamba.exe The following argument was not expected: -p Run with --helpfor more information.
Update
1
PS> micromamba self-update
특정 버전으로 업데이트도 가능하다.
1
PS> micromamba self-update--version1.4.6
micromamba 도움말.
1
PS> micromamba --help
2. micromamba 사용
micromamba의 가상환경은 micromamba activate /path/to/env 같이 활성화 시키는데, MAMBA_ROOT_PREFIX 환경변수를 기준으로 micromamba activate env 같이 사용할 수 있다.
현재 사용할 수 있는 환경을 출력.
1 2 3 4 5
PS> micromamba env list Name Active Path -------------------------------------------------------------- base C:\Users\student\micromamba C:\Users\student\miniconda3\envs\myenv
micromamba 명령으로 대부분의 conda 명령을 동일하게 실행할 수 있다.
1 2 3 4 5 6 7 8 9 10
micromamba info # 현재 micromamba 환경정보
# 설치한 패키지 목록 micromamba list ananconda # Anaconda 정보 micromamba list python # python 패키지 정보
# 설치 가능한 모든 python 패키지 목록 $ micromamba repoquery search python
# 설치 가능한 python=버전 패키지 목록 $ micromamba repoquery search "python>=3.11"
# 설치 가능한 jupyterlab 버전 패키지 목록 $ micromamba repoquery search "jupyterlab>=4.0"
# 현재 환경의 jupyterlab 에 연관된 의존성 패키지 목록 $ micromamba repoquery depends jupyterlab
# 현재 환경의 jupyterlab 에 연관된 모든 의존성 세부 목록 $ micromamba repoquery depends jupyterlab --recursive
패키지 연관 의존성을 트리형식으로 출력할 수 있다.
1 2 3 4 5 6 7 8
# 현재 환경의 jupyterlab 에 연관된 의존성 패키지의 트리 목록 $ micromamba repoquery depends -t jupyterlab jupyterlab[4.3.4] ├─ jupyter-lsp[2.2.0] │ ├─ python already visited │ └─ jupyter_server[2.15.0] │ ├─ python already visited
And you can ask for the inverse, which packages depend on some other package (e.g. ipython) using whoneeds.
1 2 3 4 5 6 7 8
$ micromamba repoquery whoneeds ipython
Name Version Build Depends Channel ------------------------------------------------------------------- jupyter_console 6.4.3 pyhd3eb1b0_0 ipython pkgs/main ipykernel 6.9.1 py39haa95532_0 ipython >=7.23.1 pkgs/main ipywidgets 7.6.5 pyhd3eb1b0_1 ipython >=4.0.0 pkgs/main With the -t,--tree flag, you can get the same information in a tree.
micromamba가 설치된 디렉토리를 찾습니다. 일반적으로 C:\Users<사용자 이름>.local\bin 또는 C:\micromamba에 설치됩니다. 해당 디렉토리를 삭제합니다.
환경 변수에서 micromamba 경로 제거:
Windows 검색 창에서 “환경 변수”를 검색하고 “시스템 환경 변수 편집”을 엽니다. “시스템 속성” 창에서 “환경 변수” 버튼을 클릭합니다. “시스템 변수” 섹션에서 “Path” 변수를 선택하고 “편집” 버튼을 클릭합니다. micromamba가 설치된 디렉토리 경로가 있는지 확인하고, 있다면 해당 경로를 삭제합니다. “확인” 버튼을 클릭하여 변경 사항을 저장합니다.
micromamba 관련 파일 삭제:
C:\Users<사용자 이름>.condarc 파일을 삭제합니다. (존재하는 경우) C:\Users<사용자 이름>.mambarc 파일을 삭제합니다. (존재하는 경우)
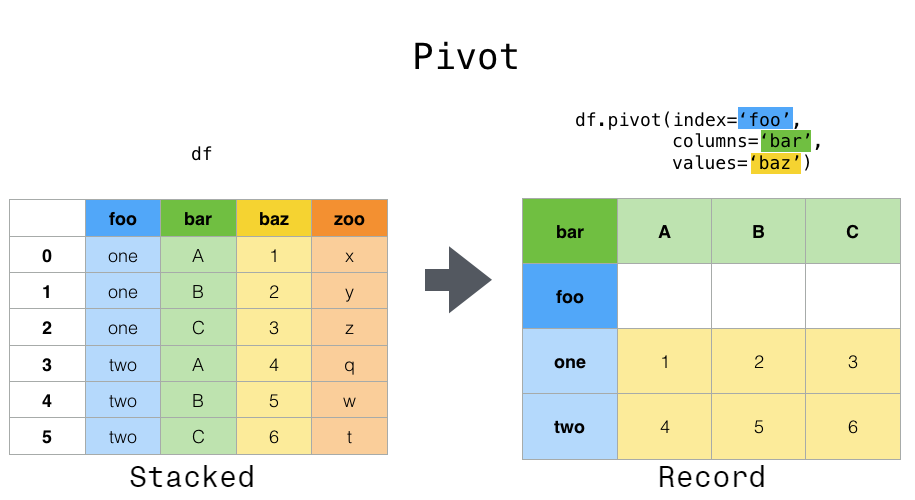
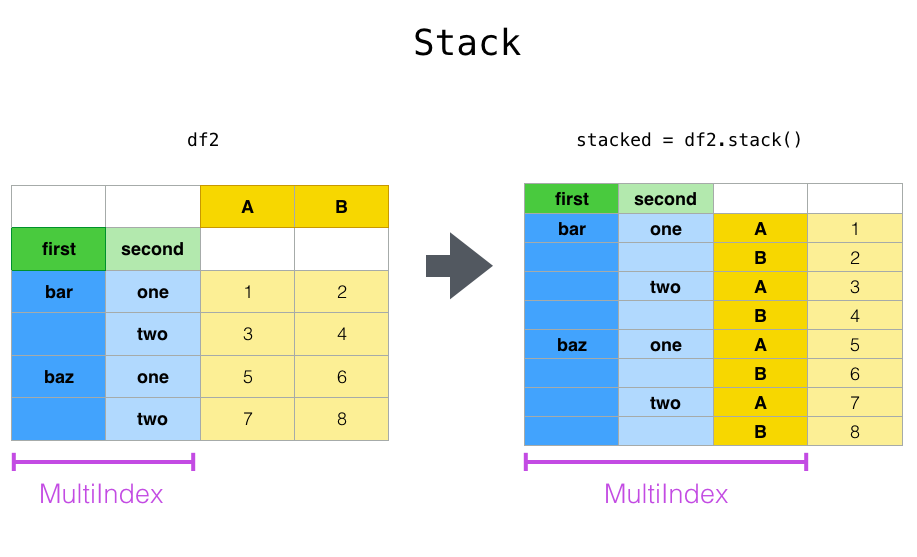
위 데이터는 stack()을 하면 A, B 컬럼이 MultiIndex 로 추가되며 A, B 컬럼 데이터 포인트가 배치된다.
1
df.stack()
first second
bar one A -1.301694
B -0.013259
two A -0.197846
B 0.879890
baz one A 0.718211
B -0.739434
two A -0.140217
B 0.071260
foo one A -1.142268
B -2.606413
two A 1.119145
B 0.109402
qux one A -0.504167
B -1.703280
two A 1.064976
B 1.011060
dtype: float64
1 2
df2 = df[:4] df2
A
B
first
second
bar
one
-1.301694
-0.013259
two
-0.197846
0.879890
baz
one
0.718211
-0.739434
two
-0.140217
0.071260
1 2
stacked = df2.stack() stacked
first second
bar one A -1.301694
B -0.013259
two A -0.197846
B 0.879890
baz one A 0.718211
B -0.739434
two A -0.140217
B 0.071260
dtype: float64
> with np.printoptions(precision=3): > print( np.array([2.0]) / 3 )
pandas 숫자 출력 형식 변경
pandas에서 몇 가지 옵션을 바꾸는 방법을 정리해 보자. pandas의 옵션은 pd.options 를 사용한다.
pd.options.display
출력의 형태, 표기를 변경하는 것은 pd.options.display 아래에 있다. 여기서 사용할 수 있는 옵션은 describe_option() 으로 확인할 수 있다.
1 2 3 4 5 6 7
> pd.describe_option() compute.use_bottleneck : bool Use the bottleneck library to accelerate if it is installed, the default isTrue Valid values: False,True [default: True] [currently: True] ...
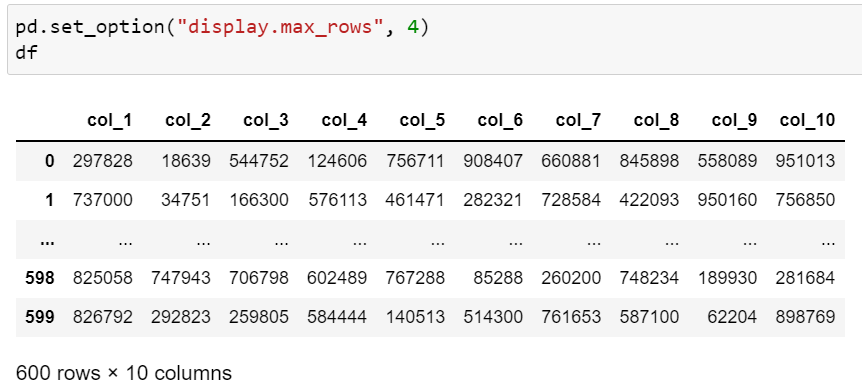
- row, column 출력 개수 조정
pd.options.display.max_rows : 표를 출력할 때 최대 행 수입니다.
pd.options.display.min_rows : 표를 출력할 때 최소 행 수입니다.
1 2 3 4 5
import pandas as pd > pd.options.display.max_rows 60 > pd.options.display.min_rows 10
pd.describe_option(OPTIONS) 를 사용하면 해당 옵션에 대한 설명을 출력해 준다.
1 2 3 4 5
> pd.describe_option("max_rows") display.max_rows : int If max_rows is exceeded, switch to truncate view. Depending on `large_repr`, objects are either centrally truncated or printed as a summary view. 'None' value means unlimited.
[project] name = "example_package_YOUR_USERNAME_HERE" version = "0.0.1" authors = [ { name="Example Author", email="author@example.com" }, ] description = "A small example package" readme = "README.md" requires-python = ">=3.7" classifiers = [ "Programming Language :: Python :: 3", "License :: OSI Approved :: MIT License", "Operating System :: OS Independent", ]
This is a simple example package. You can use [Github-flavored Markdown](https://guides.github.com/features/mastering-markdown/) to write your content.
LICENSE 파일에 저작권을 명시한다.
1 2 3
Copyright (c) 2018 The Python Packaging Authority
Permission is hereby granted, free of charge, to any person obtaining a copy
배포 묶음 생성하기
배포를 위한 build 도구를 설치한다.
1
python3 -m pip install --upgrade build
packaging_tutorial 폴더 아래 pyproject.toml 파일이 있는 위치에서 배포를 위한 build 명령으로 소스를 패키징을 한다.
build 를 수행하면 별도의 venv 가상환경을 생성해서 의존성에 명시된 setuptools 등을 설치하고 빌드를 진행한다.
1 2 3 4 5 6 7
> python3 -m build * Creating venv isolated environment... * Installing packages in isolated environment... (setuptools>=61.0) ... ... removing build\bdist.win-amd64\wheel Successfully built example_package_YOUR_USERNAME_HERE-0.0.1.tar.gz and example_package_YOUR_USERNAME_HERE-0.0.1-py3-none-any.whl
이 명령의 결과로 dist 폴더에 우리 프로젝트에 대한 배포용 패키징으로 소스 패키징 .gz 파일, built distribution 패키징 .whl 2개의 파일이 생성된다.
회사 등에서 방화벽을 사용하는 경우 pip / conda 저장소에서 패키지 설치가 안되는 경우가 있다. 또한 방화벽 안에서 설치할 경우 SSL verification error 에러 발생으로 설치가 안되기도 한다. 이런 경우 직접 pip 혹은 conda 설치가 안되는 경우에 프락시 지정을 해서 사용이 가능하다.
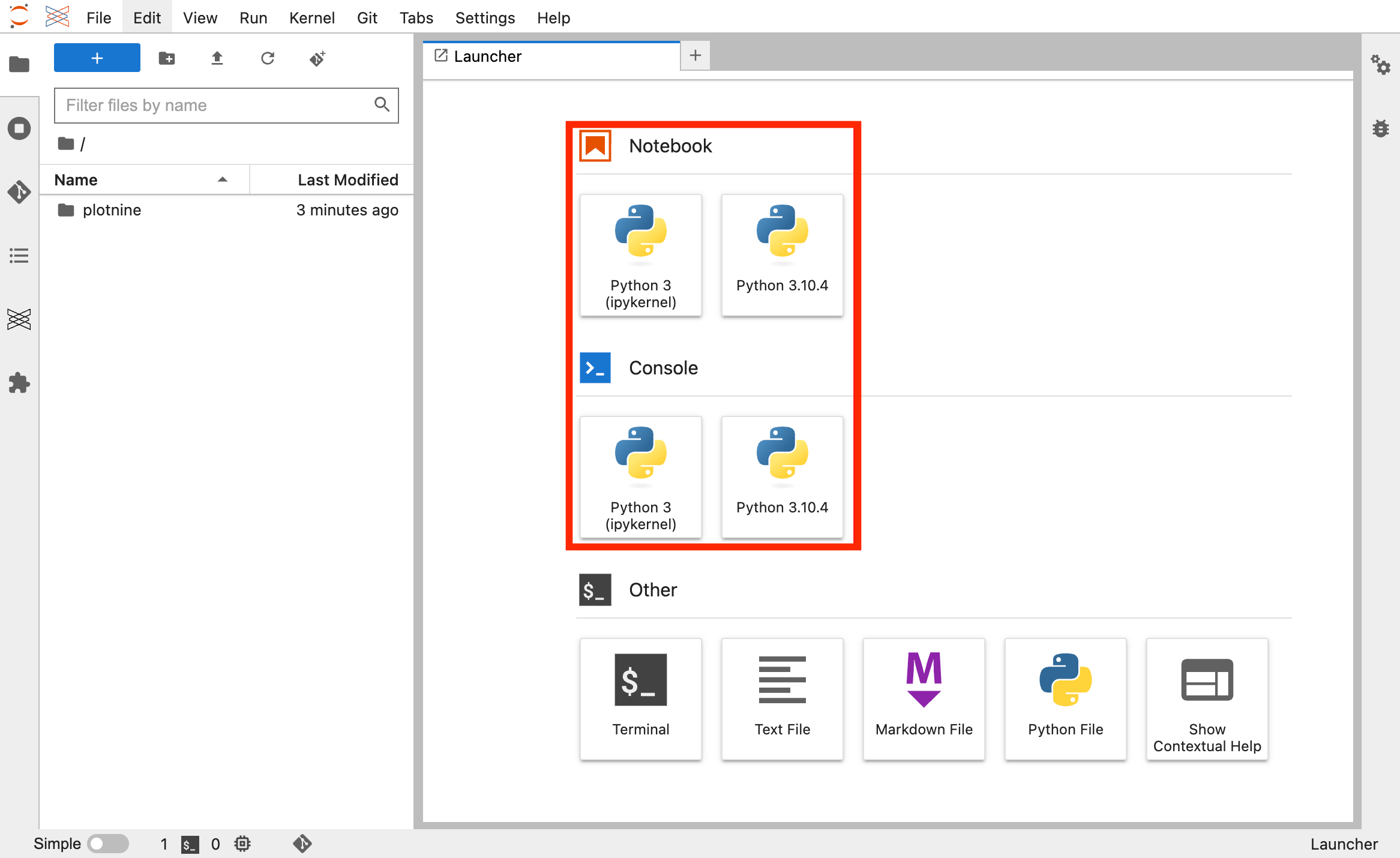
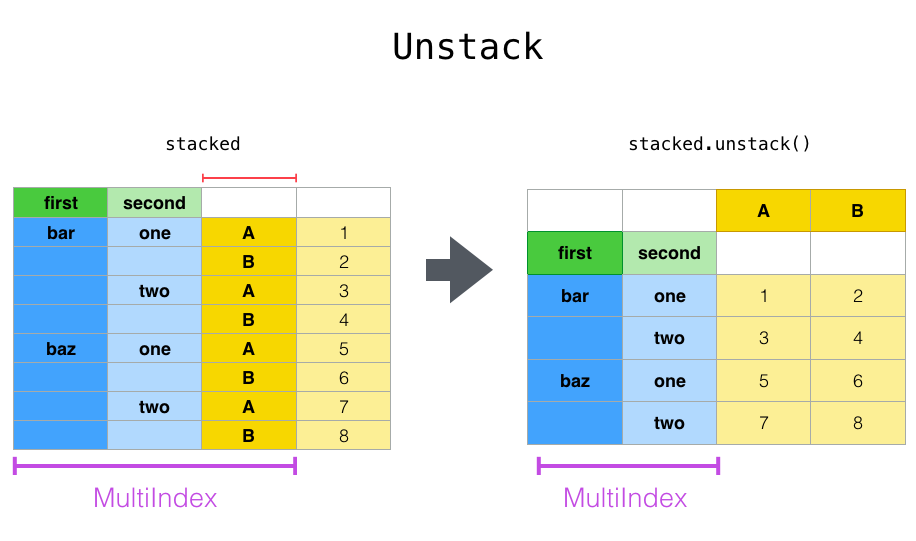
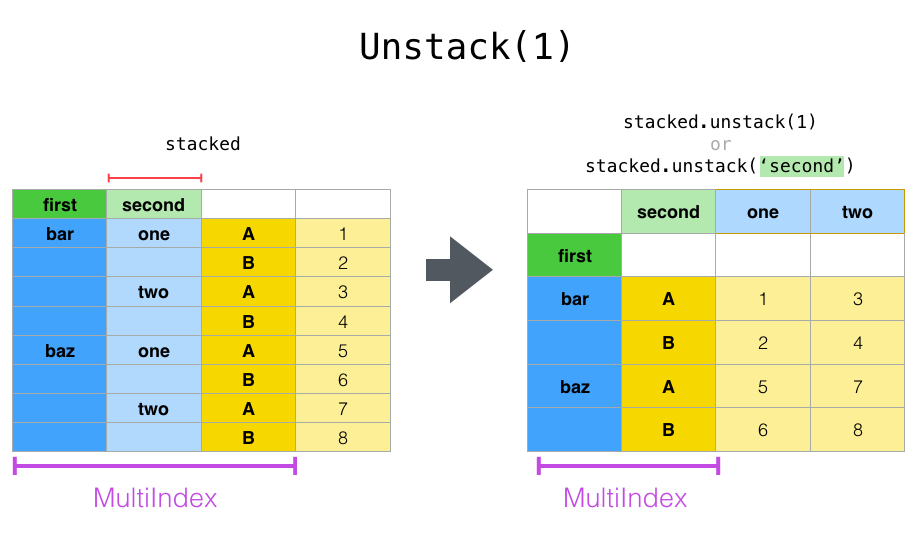
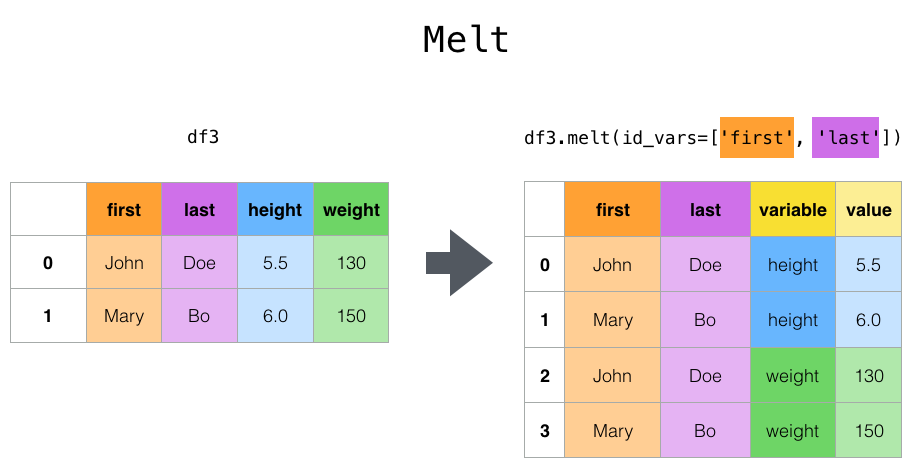
 이미지 참조
이미지 참조